Запуск ChatGPT в ноябре 2022 г. стал переломным моментом в обработке естественного языка (NLP), поскольку продемонстрировал поразительную эффективность архитектуры трансформеров для понимания и генерации текстовых данных. Сейчас мы наблюдаем нечто подобное в области компьютерного зрения, когда появляются предварительно обученные большие модели зрения (Large Vision Models, LVM). Шринивас Куппа, директор по стратегии и продуктам SymphonyAI, поставщика решений в области искусственного интеллекта для различных отраслей, рассказал порталу BigDATAwire о том, когда эти модели обеспечат широкое использование визуальных данных.
Примерно с 2010 г. новейшим достижением в области компьютерного зрения стала сверточная нейронная сеть (CNN), которая представляет собой тип архитектуры глубокого обучения, моделирующий взаимодействие нейронов в биологическом мозге. Фреймворки CNN, такие как ResNet, обеспечили решение задач компьютерного зрения, таких как распознавание и классификация изображений, и нашли некоторое применение в промышленности.
За последние примерно десять лет в области компьютерного зрения получил распространение другой класс моделей, известных как диффузионные. Диффузионные модели — это тип генеративных нейронных сетей, использующих процесс диффузии для моделирования распределения данных, которые затем могут быть использованы для генерации данных аналогичным образом. Среди популярных диффузионных моделей — Stable Diffusion, открытая модель генерации изображений, предварительно обученная на 2,3 млрд. изображений из англоязычного Интернета, которая способна генерировать изображения на основе введенного текста.
Необходимо внимание
Серьезный сдвиг в архитектуре произошел в 2017 г., когда Google впервые предложила архитектуру трансформеров в своей работе «Attention Is All You Need». Эта архитектура основана на принципиально ином подходе. Она отказывается от сверток и рекуррентных CNN и рекуррентных нейронных сетей RNN (используемых в основном для NLP) и полностью полагается на так называемый механизм внимания, при котором относительная важность каждого компонента в последовательности вычисляется относительно других компонентов в последовательности.
Этот подход оказался полезным в NLP, где его впервые применили исследователи Google, и непосредственно привел к созданию больших языковых моделей (LLM), таких как генеративный предварительно обученный трансформер (GPT) компании OpenAI, который «зажег» область генеративного ИИ. Но оказалось, что основной элемент архитектуры трансформеров — механизм внимания — не ограничивается NLP. Точно так же, как слова можно кодировать в токены и измерять их относительную важность с помощью механизма внимания, пикселы изображения тоже можно кодировать в токены и вычислять их относительную ценность.
Работа с трансформерами для компьютерного зрения началась в 2019 г., когда исследователи впервые предложили использовать архитектуру трансформеров для задач компьютерного зрения. С тех пор исследователи совершенствуют LVM. Google выложила в открытый доступ ViT, модель трансформера зрения, а Meta (компания признана экстремистской и запрещена в РФ) — DINOv2. OpenAI также разработала LVM на основе трансформеров, например CLIP, и включила в свою GPT-4v генерацию изображений. LandingAI, основанная соучредителем Google Brain Эндрю Ын, также использует LVM в промышленных целях. Мультимодальные модели, которые могут обрабатывать как текст, так и изображение, а также генерировать как текст, так и изображение, сегодня доступны у нескольких поставщиков.
LVM на основе трансформеров имеют свои преимущества и недостатки по сравнению с другими моделями компьютерного зрения, включая диффузионные модели и традиционные CNN. С одной стороны, LVM более требовательны к данным, чем CNN. Если у вас нет значительного количества изображений для обучения (LandingAI рекомендует минимум 100 тыс. немаркированных изображений), то эта модель может вам не подойти.
С другой стороны, механизм внимания дает LVM фундаментальное преимущество перед CNN: в них с самого начала заложен глобальный контекст, что приводит к более высоким показателям точности. Вместо того чтобы пытаться идентифицировать изображение, начиная с одного пиксела и увеличивая масштаб, как это делает CNN, LVM «медленно приводит в фокус все размытое изображение».
Одним словом, доступность предварительно обученных LVM, которые обеспечивают очень высокую производительность «из коробки» и не требуют ручного обучения, может стать таким же прорывным фактором для компьютерного зрения, как и предварительно обученные LLM для рабочих нагрузок NLP.
LVM на пороге
Появление LVM волнует отраслевых экспертов. По словам Шриниваса Куппы из SymphonyAI, благодаря LVM мы стоим на пороге больших перемен на рынке компьютерного зрения. «Мы начинаем видеть, что большие модели компьютерного зрения повторяют путь больших языковых моделей», — говорит он.
По мнению Куппы, большое преимущество LVM заключается в том, что они уже (в основном) обучены, что избавляет клиентов от необходимости начинать обучение модели с нуля. «Прелесть этих больших моделей зрения, аналогичных большим языковым моделям, в том, что они в значительной степени предварительно обучены, — говорит он. — Самая большая проблема для ИИ в целом и, конечно, для моделей зрения заключается в том, что как только вы добираетесь до клиента, вам нужно получить от него большое количество данных для обучения модели».
SymphonyAI использует различные LVM в работе с клиентами на производстве, в сфере безопасности и в розничной торговле, большинство из которых имеют открытый исходный код и доступны на Huggingface. Среди них Pixel, модель с 12 млрд. параметров от Mistral, а также LLaVA, мультимодальная Open Source-модель.
Хотя предварительно обученные LVM хорошо работают в различных сценариях, SymphonyAI обычно настраивает модели, используя собственные графические данные, что повышает производительность для конкретных сценариев использования. «Мы берем базовую модель и дорабатываем ее, прежде чем передать заказчику, — поясняет Куппа. — Поэтому, когда мы оптимизируем какую-то версию, она становится в несколько раз лучше. И это сокращает время создания стоимости для клиента, так что ему не нужно работать со своими собственными изображениями, маркировать их и беспокоиться о них до того, как он начнет их использовать».
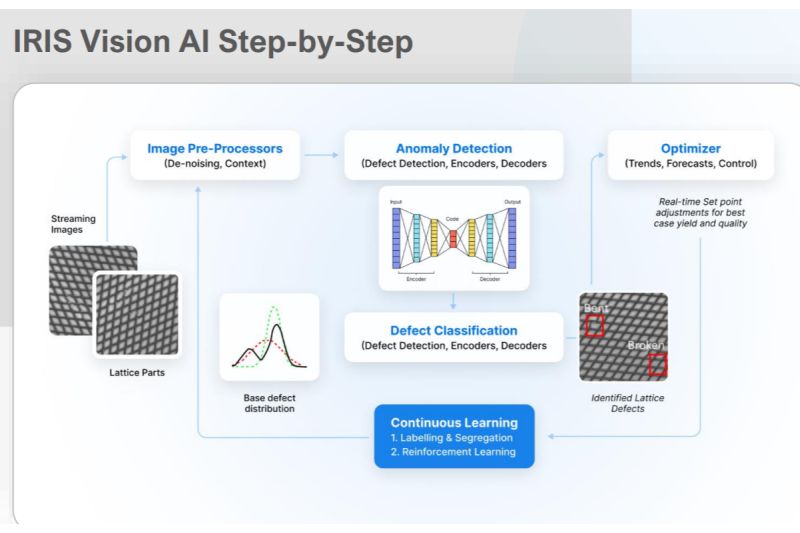
Например, многолетний опыт работы в сфере дискретного производства позволил SymphonyAI получить множество изображений распространенных элементов оборудования, таких как котлы. Компания может точно настроить LVM, используя эти изображения. Затем модель используется как часть предложения Iris, чтобы распознать, когда оборудование повреждено или когда не было проведено техническое обслуживание.

«Нас объединяет множество приобретений, которые происходили на протяжении 50 или 60 лет, — рассказывает Куппа о компании SymphonyAI, которая была официально основана в 2017 г. и получила инвестиции в размере 1 млрд. долл. от Ромеша Вадхвани, индийско-американского бизнесмена. — Поэтому со временем мы накопили много данных правильным способом. С момента появления генеративного ИИ мы стали изучать, какие данные у нас есть, анонимизировать их, насколько это возможно, и затем использовать их в качестве основы для обучения моделей».
LVM в действии
«Я надеюсь, что LVM привлекут к себе внимание и начнется ускоренный рост, — говорит Куппа. — Я вижу достаточно моделей, доступных на Huggingface. Я знаю несколько моделей с открытым исходным кодом, которые мы можем использовать. И я думаю, что есть возможность значительно расширить использование LVM».
Одним из ограничивающих LVM факторов (помимо необходимости их тонкой настройки для конкретных сценариев использования) являются требования к аппаратному обеспечению. LVM имеют миллиарды параметров, в то время как CNN, такие как ResNet, обычно ограничиваются только миллионами параметров. Это увеличивает требования к локальному оборудованию, необходимому для работы LVM в режиме вывода.
Для принятия решений в реальном времени LVM необходимо значительное количество вычислительных ресурсов. Во многих случаях для этого требуется подключение к облаку. По словам Куппы, доступность различных типов процессоров, включая ПЛИС, может помочь в этом, но, тем не менее, это актуальная проблема.
Хотя в настоящее время использование LVM не так велико, его масштабы растут. За последние два года количество пилотных проектов и проверок концепций значительно выросло, и возможности для их реализации очень велики.
«Благодаря тому, что модели предварительно обучены, сокращается время получения выгоды, поэтому предприятия могут гораздо быстрее оценить ценность модели и результаты без предварительных инвестиций, — говорит Куппа. — Сейчас проводится гораздо больше проверок концепций и пилотных проектов. Но нам еще предстоит увидеть, как это воплотится в масштабное внедрение на уровне предприятия».