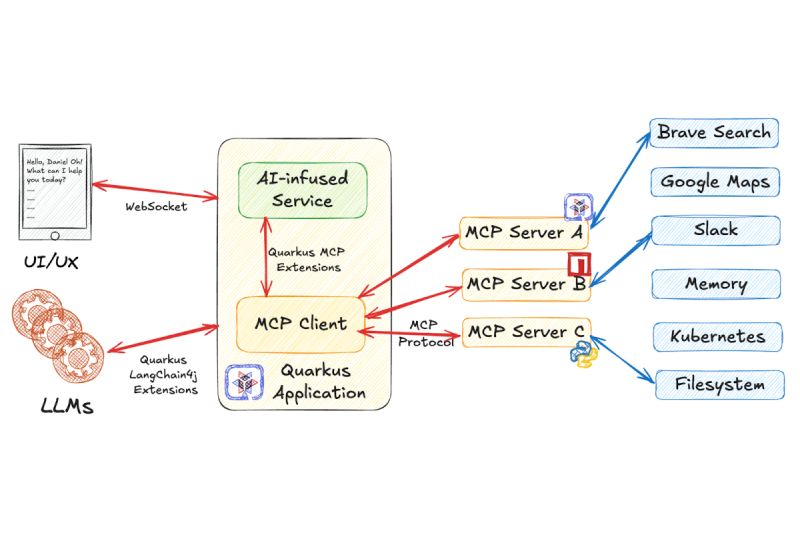




Эндрю Миллс, старший архитектор решений NetApp Instaclustr, приводит на портале ITPro Today комплексное руководство по выбору и внедрению технологий нативно-облачного (cloud-native) уровня данных.
Если вы еще не перешли на нативные облачные технологии, вы уже отстали. Благодаря экспоненциальному росту после начала пандемии облако стало основным источником данных. Независимо от того, создаете ли вы систему с нуля или переносите существующую, выбор правильного нативно-облачного стека данных имеет решающее значение. В этой статье я расскажу о специфике и покажу, как сделать правильный выбор.
Cloud-Native набирает обороты: вот почему
Мы живем в условиях экономики «пять девяток», а это значит, что ваш онлайн-сервис или приложение не может простаивать более 26 секунд в месяц. В отличие от традиционных технологий, на которых обычно работают монолитные серверные приложения, переход на облачные технологии позволяет компаниям обслуживать клиентов в глобальном масштабе, не испытывая проблем с доступностью и производительностью.
Вот несколько основных причин такого сейсмического сдвига:
- Облачные технологии обычно основаны на моделях ценообразования, основанных на потреблении. Это позволяет пользователям плавно управлять ресурсами, не перерасходовать их и платить только за использованные ресурсы.
- Масштабируемость становится необременительной, и компании могут увеличивать (или уменьшать) масштабы в зависимости от потребностей пользователей и рынка. Такая гибкость избавляет от операционных накладных расходов и узких мест в производительности.
- Миграция также становится легкой благодаря повышенной переносимости и отсутствию привязки к поставщику. Предприятия могут без особых проблем переходить на другую систему в зависимости от своих бизнес- и технических требований.
- Автоматизация становится проще — от разработки до развертывания и управления. Это позволяет предприятиям работать бережливо, не тратя деньги на персонал и ресурсы.
- Создание изолированных сервисов с помощью контейнеров и микросервисов повышает безопасность. Благодаря такой изоляции один скомпрометированный компонент не влияет на общий уровень безопасности.
В общем, окупаемость инвестиций неоспорима.
Выбор технологий уровня данных: шпаргалка
Как уже говорилось ранее, архитекторы нативных облачных решений сталкиваются с критической проблемой выбора правильной технологии уровня данных, способной масштабироваться, обеспечивать высокую доступность и удовлетворять постоянно растущий список требований безопасности. При этом они должны делать это без излишней сложности и дополнительных затрат. Но как сделать правильный выбор при таком количестве вариантов?
Вот краткий контрольный список, который поможет вам встать на правильный путь:
1. Выбор правильных инструментов уровня данных для вашей архитектуры
Подбор правильного инструмента к рабочей нагрузке очень важен для того, чтобы все работало как надо. Поэтому убедитесь, что вы делаете правильный выбор. Например, используйте Apache Cassandra для распределенных транзакций высокой доступности, Apache Kafka для потоковой передачи событий в реальном времени, ClickHouse для анализа больших объемов структурированных данных и OpenSearch для полнотекстового поиска и аналитики.
2. Приоритет масштабируемости и доступности
Если ваша архитектура требует 99,99% времени безотказной работы, вместо традиционной реляционной базы данных рассмотрите возможность использования горизонтально масштабируемых баз данных без выделенного узла-лидера (leaderless), таких как Apache Cassandra. Это связано с тем, что последняя масштабируется двумя способами: с помощью репликации или с помощью архитектуры «основной/вторичный».
3. Сокращение технического долга и проблем с наймом персонала
Традиционный путь не так уж плох, но он создает множество проблем, таких как внедрение, обучение и наем специалистов, чтобы все работало как надо. Выбирайте нативные облачные технологии и Open Source-технологии с сильной поддержкой сообщества и широким распространением, чтобы обеспечить долгосрочную работоспособность и облегчить доступ к квалифицированным специалистам.
4. Понимание моделей лицензирования
Все Open Source-инструменты уровня данных имеют свои собственные уникальные условия лицензирования. Прежде чем приступать к работе, убедитесь, что вы понимаете все тонкости коммерческого использования, особенно когда речь идет о распространении и производной деятельности.
Вот некоторые сведения о лицензировании, которые вам следует принять во внимание:
- PostgreSQL — лицензия PostgreSQL (аналогична лицензии MIT).
- MySQL — коммерческая лицензия и лицензия General Public License (GPL).
- SQLite — общественное достояние.
- Apache Cassandra — лицензия Apache License 2.0.
- MariaDB — лицензия GNU General Public License (GPL).
5. Оптимизация для интеграции
Избегайте изолированности данных, выбирая технологии, которые дополняют друг друга. Например, ваша экосистема может включать Apache Kafka для архитектуры, ориентированной на события, Apache Spark для пакетной и потоковой аналитики и OpenSearch для индексирования журналов и событий. Все они хорошо работают вместе, не создавая серьезных проблем с интеграцией или совместимостью.
6. Рассмотрение компромиссов
Базы данных NoSQL жертвуют соответствием ACID ради масштабируемости. С другой стороны, архитектуры, управляемые событиями, добавляют гибкости, но требуют тщательной оркестрации для достижения оптимальных результатов. Сделать правильный выбор — значит сбалансировать эти компромиссы, исходя из приоритетов бизнеса и технических требований. Это должно быть неотъемлемой частью вашей стратегии.
7. Правильная миграция в облако
Когда вы готовы к миграции в облако, избегайте распространенного подхода без модификации «поднять и перенести» («lift and shift»). Настоятельно рекомендуется перестроить архитектуру приложений и изменить данные, прежде чем переносить все в облако. Это поможет избежать проблем с совместимостью, которые могут привести к потере данных, низкой производительности и даже серьезным простоям в крайних случаях.
Дьявол кроется в метриках
После создания облачной экосистемы данных вам нужно найти способ контролировать все и следить за стабильностью результатов. Именно здесь в игру вступают метрики.
Пользователи Postgres должны следить за:
- Метрики транзакций. Всегда отслеживайте длительность транзакций. Невыполнение этого требования может привести к увеличению задержек и блокировке ресурсов. Существуют также показатели фиксации и отката. Первый — это количество завершенных транзакций, которые были зафиксированы в базе данных. Это число должно быть высоким. Показатель откатов указывает на потенциальные проблемы с блокировками транзакций и SQL-запросами.
- Незакрытые соединения. Приложения часто открывают соединения и не закрывают их. Это создает значительную нагрузку на вашу инфраструктуру, если игнорировать эту проблему. Вам необходимо постоянно отслеживать и сравнивать количество открытых соединений с теми, которые действительно используются приложением. Отсутствие логической корреляции означает, что вам нужно кое-что «почистить».
Для проверки соединений PostgreSQL используйте следующий SQL-запрос:
SELECT state, count(*)
FROM pg_stat_activity
GROUP BY state; - Метрики использования памяти. Коэффициент эффективности буферного кэша (buffer cache hit ratio), показывает, как часто Postgres считывает данные из буферного кэша, а не обращается к данным на диске. Высокий коэффициент означает, что кэш хорошо обслуживает запросы данных, что приводит к оптимальной производительности. Отслеживайте общее использование памяти и постоянно выявляйте узкие места в ней.
Используйте этот SQL-запрос для расчета коэффициента эффективности буферного кэша:
SELECT
round((sum(blks_hit) / nullif(sum(blks_hit) + sum(blks_read), 0)) * 100, 2) as cache_hit_ratio
FROM
pg_stat_database; - Активные и неактивные соединения. Как следует из названия, активные соединения относятся к тем, которые в данный момент выполняют запросы, их большое количество может свидетельствовать о чрезмерной загруженности базы данных. Неактивные соединения — это открытые соединения, которые не выполняют запросы. Наличие большого количества неиспользуемых соединений приводит к растрате ценных ресурсов, создает накладные расходы и влияет на производительность.
Это лишь верхушка айсберга. Используйте такие инструменты, как Grafana и Prometheus, для мониторинга ключевых показателей. Вы просто не можете позволить себе быть посредственностью на сегодняшних жестоких рынках.
Использование Apache Cassandra можно оптимизировать с помощью отслеживания:
- Пропускная способность. Постоянно отслеживайте уровень запросов на чтение (Read Request Rate, количество запросов на чтение, поступающих от клиентов за одну секунду) и уровень запросов на запись (Write Request Rate, количество запросов на запись, поступающих от клиентов за одну секунду). Следите за нагрузкой, чтобы добиться практически линейной масштабируемости.
- Кэш. Apache Cassandra предлагает эффективную функцию кэширования с помощью кэша ключей и кэша строк, последний из которых не включен по умолчанию. Отслеживайте показатели эффективности кэша в хранении и извлечении данных (hit ratio), показатели успешно обслуженных из кэша запросов (hit rate), размеры и использование обоих кэшей.
- Латентность. Отсутствие отслеживания задержки может привести к неудаче в обнаружении таких проблем, как проблемы с моделью данных и ограничения возможностей обработки. Задержки чтения и записи обычно измеряются в формате гистограммы с
50-м, 75-м, 95-м, 98-м, 99-м и99,9-м процентилями. Это позволяет получить представление о распределении задержек во времени. - Использование диска. Использование диска динамично, и вам нужно следить за колебаниями уровня и шаблонов, сохраняя около 30% свободного пространства для временных операций, таких как уплотнение.
- Уплотнение. Отслеживание производительности уплотнения очень важно для общего понимания ситуации. Всегда следите за коэффициентом уплотнения, скоростью компактирования данных и выполнением заданий по уплотнению.