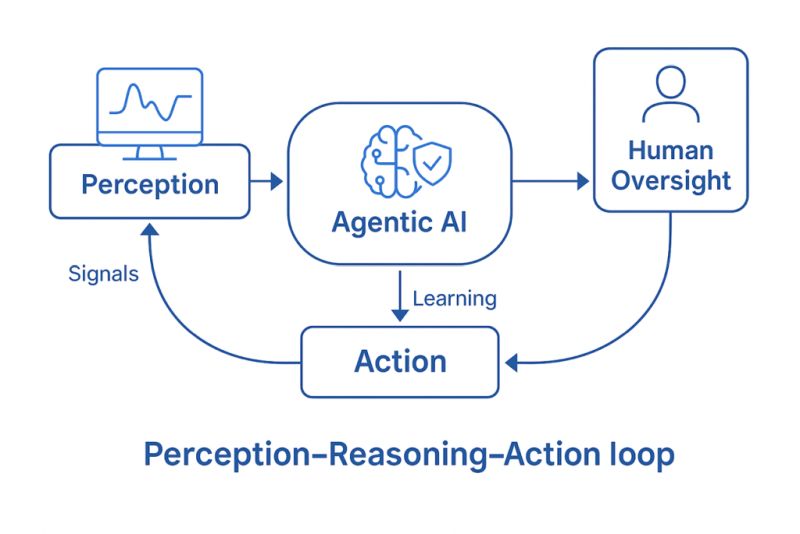
Ученые из Массачусетского технологического института разработали программный алгоритм под названием Taco, который позволяет автоматизировать компрессию тензорных таблиц (3D-матриц), состоящих из большого количества пустых данных, пишет издание Science Daily. Систему назвали по аббревиатуре для компилятора тензорной алгебры (tensor algebra compiler). Тензор — это многомерный аналог матрицы, а данные, которые необходимо обработать, обычно хранятся в матрицах. Эффективностью метод обязан математическим операциям, проводимым на тензорах: они работают быстрее, чем аналогичные операции с матрицами, если каждой последовательности тензорных операций выделен собственный шаблон расчёта.
В реальном мире тензорные таблицы используют для составления карт для баз данных, например, в Amazon, где ID покупателя соотносится с товарами. Причем, в матрицу помещаются все имеющиеся у магазина товары, напротив которых единицей отмечается факт покупки. Эти данные можно, в свою очередь, связать с рейтингом покупателя и его отзывами, которые хранятся в другой таблице. Подобные матрицы более удобны для анализа больших данных и машинного обучения, нежели обычные SQL-базы. Однако у них есть очевидный минус: при умножении таблиц это создает ненужную нагрузку на процессор и забивает память нулевыми данными.
Тем временем Taco совершает множественные расчёты в рамках одного цикла, или так называемого ядра. Один из авторов предложенной системы, Фредрик Кьолстад, добавляет: «Если все операции происходят в одном ядре, все вычисления производятся быстрее, без дополнительного помещения промежуточных результатов в память с последующим чтением из неё. Подход Тасо всё делает в одну итерацию». Он также отметил, что его группа разработала разные ядра для наиболее встречающихся операций с тензорами при обработке больших данных. Число возможных ядер, которые другие учёные смогут создать, основываясь на предложенных, бесконечно. Отметим, что для работы c Taco программисту необходимо указать лишь размерность используемого тензора, является ли он полностью разрежённым и директорию, где находится файл с данными.
В работе Taco использует эффективный механизм индексирования, чтобы хранить только ненулевые значения разреженных тензоров. Для сравнения, массив информации Amazon с нулевыми значениями будет содержать примерно 107 Эб, но с системой сжатия Taco он займёт всего 13 Гб, которые можно обработать весьма быстро.
Эта разработка интересна многим бизнесам и университетам. Анализ больших данных позволяет исследователям и специалистам компаний быть лучше информированными об интересующих их процессах и быстрее принимать эффективные решения, отбрасывая ненужные или неиспользуемые данные. Применяя сложные технологии анализа, такие как анализ текста, машинное обучение, сбор данных, построение прогнозов, обработку статистики, будет возможно фокусироваться на новых, ранее незамеченных источниках данных, и грамотнее расходовать свои ресурсы.
Ранее IBM разработала способ имитации квантового