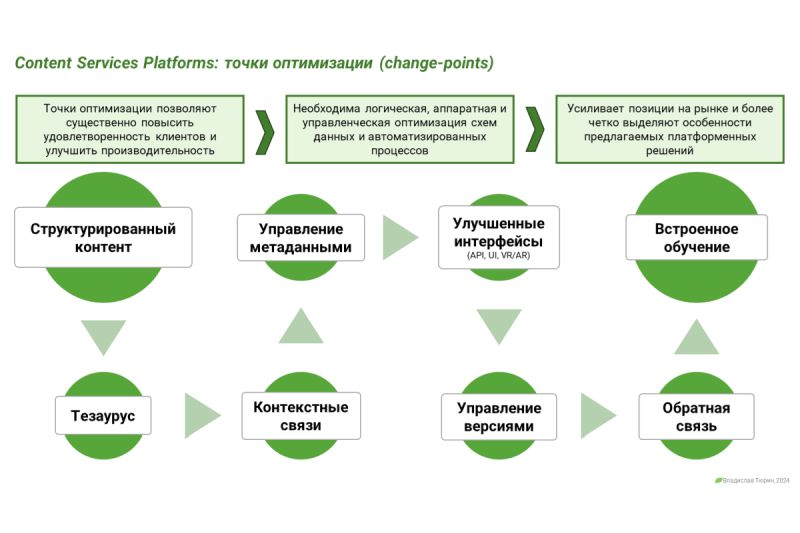
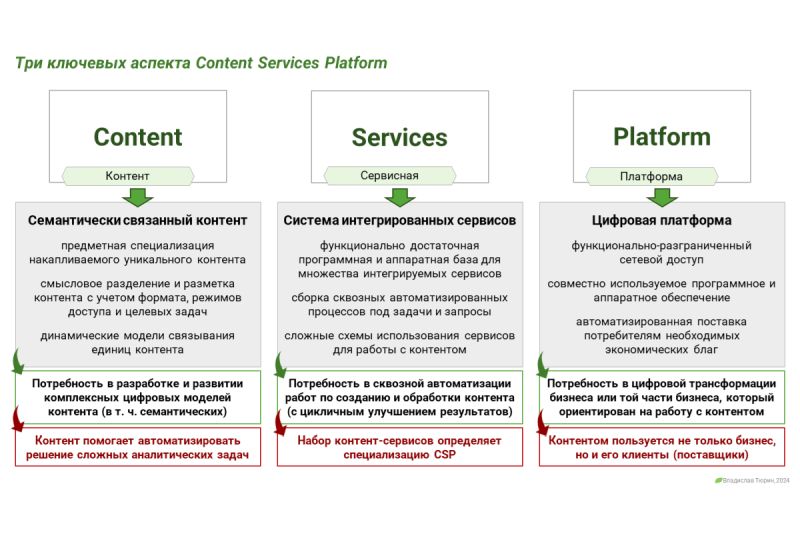
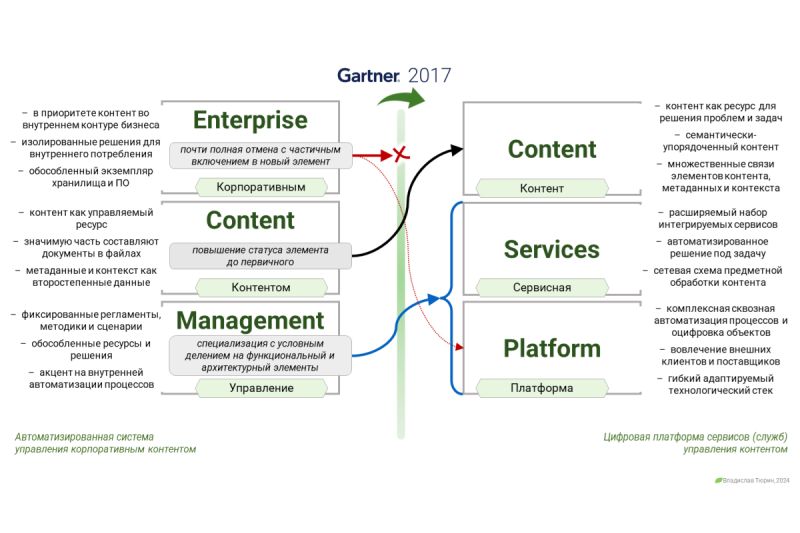
Отраслевые эксперты рассказывают на портале Information Age о способах решения проблем обработки контента при роботизации бизнес-процессов (robotic process automation, RPA).
RPA призвана выполнять роль цифровых ассистентов для сотрудников. Известно, что она полезна для упрощения бизнес-операций без повышения затрат и уменьшения числа допускаемых человеком ошибок. Однако из-за интеллектуальной несовместимости это ПО допускает ошибки при обработке контента.
Дополнительная интеграция
Один из способов устранения подобных проблем заключается в интегрировании RPA с другими интеллектуальными технологиями.
«RPA в основном применяется для автоматизации основанных на правилах процессов и воспроизведения действий человека, таких как обработка счетов-фактур и ввод данных из таблиц Microsoft Excel в системы SAP или Oracle, — пояснил Гопал Рамасубраманиан, старший директор фирмы Cognizant по интеллектуальной автоматизации и технологиям. — Однако, когда речь заходит об обработке документов, возникает необходимость в дополнительных технологиях «умного» ввода данных, сочетающего оптическое распознавание символов (OCR), обработку естественного языка (NLP) и машинное обучение (ML) для выделения из документов метаданных и автоматизации обработки.
Он отметил, что контент может быть различных типов: например, структурированный/печатный, структурированный/рукописный, неструктурированный/печатный и неструктурированный/рукописный. «Весьма просто выделить структурированный контент с помощью стандартных технологий OCR. Однако выделение неструктурированного контента представляет трудность, и для ее преодоления все чаще применяются NLP и ML», — добавил эксперт.
Арпит Оберой, специалист по RPA из компании delaware, полагает, что основная проблема, с которой сталкивается сегодня технология RPA, связана с тем фактом, что она часто все еще с трудом обрабатывает неструктурированные контент и данные. Для преодоления сохраняющихся здесь трудностей организации могут попробовать преобразовать свои данные в более структурированные наборы и там, где это возможно, объединить RPA с ИИ, чтобы оптимизировать или автоматизировать обработку контента.
Привлечение сторонних разработчиков
Эндрю Рейнер, вице-президент компании UiPath в регионе EMEA по профессиональным сервисам, указывает на необходимость объединения RPA с приложениями сторонних производителей.
«Исторически технология RPA могла интегрироваться с приложениями других компаний, которые помогали обрабатывать контент, — сказал Рейнер. — Например, многие производители OCR (Abbyy, IBM и др.) допускают прямую интеграцию, позволяющую классифицировать или распознавать полуструктурированные или структурированные документы». По его словам, UiPath также серьезно инвестировала в распознавание документов, чтобы создать готовое решение для клиентов, гибко применяющее различные техники, такие как сопоставление с образцом, создание шаблонов и ML при работе с неструктурированным и полуструктурированным типами документов«.
«Когда мы начинаем более широко мыслить об обработке контента, это хорошо укладывается в концепцию гиперавтоматизации, — продолжал Рейнер. — Длительные рабочие процессы с участием человека позволяют роботам и людям гармонично сотрудничать при осуществлении операций. Это дает огромные преимущества с точки зрения подключения приложений к обработке контента через интерфейс пользователя или API. С включением ML в RPA роботы получили возможность классифицировать и понимать эмоции, предлагать лучшие варианты дальнейших действий по отношению к неструктурированному контенту».
Инвестируйте в инструменты, но с осторожностью
Хотя помощь в виде дополнительного ПО будет не лишней, организациям следует проявлять осторожность, чтобы избежать ненужных расходов, и приобретать инструменты для достижения четких, конкретных целей.
«У компаний имеется множество неструктурированных данных в различных форматах — документы, сообщения электронной почты или даже данные систем, которые не структурированы, такие как платежные данные для выверки, — сказал Крис Портер, генеральный директор компании NexBotix. — Здесь у RPA возникает проблема, поскольку данная технология может работать только со структурированными, основанными на правилах цифровыми процессами. У клиентов есть несколько способов преодоления этого недостатка. Один из них — купить адаптированное точечное решение вроде инструмента OCR, которое может выделять данные из документов. Другой — приобрести инструмент для управления потоками работ и с его помощью оркестрировать роботов и людей. Можно также взять у Google на пробу инструмент машинного обучения и выделять знания из сложных документов. Эти инструменты призваны решать очень узкий спектр проблем с жесткими параметрами».
Однако, считает он, у каждого из таких инструментов имеются свои технические проблемы. «Приступая к одному из этих проектов, вы столкнетесь с необходимостью значительных затрат. Кроме того, потребуются соответствующие специалисты для поддержки каждой инициативы. Любой сценарий использования следует рассматривать в качестве самостоятельного проекта, потому что фактически вы покупаете решение для удовлетворения конкретной потребности. И если в вашей организации много различных типов данных и много различных процессов, в которых используются неструктурированные данные, вам каждый раз придется начинать все заново и покупать подходящее решение для устранения каждой отдельной проблемы. Главное применять нужную технологию для решения проблем, но делать это с учетом масштабирования, сосредоточившись на ценности для бизнеса», — добавил эксперт.
Интеллектуальная обработка контента
Окончательным способом преодоление недостатков RPA при обработке контента является использование дополнительных возможностей.
«Самой большой проблемой RPA является неспособность обрабатывать неструктурированный контент, такой как счета-фактуры, сообщения электронной почты, формы, рецепты или корреспонденция. Однако компании могут ее решить и решают, — отметил Нейл Мерфи, глобальный вице-президент ABBYY. — Все, что для этого нужно, — это интеллектуальная работа с контентом (content intelligence), которая делает боты RPA умнее, добавляя им когнитивные способности, такие как способность анализировать, понимать и обрабатывать неструктурированный контент. Организации могут использовать такой подход благодаря простым в использовании решениям, не требующим программирования или требующим минимального программирования, которые позволяют персоналу создавать ботов RPA, способных обрабатывать огромные массивы документов». По его словам, эти решения уже начинают использоваться компаниями всех размеров, устраняя входной технологический барьер. Это, в свою очередь, стимулирует инновации. «Некоторые компании объединяют такие возможности, чтобы предложить передовую интеллектуальную обработку контента в сложных случаях. Хорошим примером является онбординг клиентов, когда имеется множество документов, нуждающихся в обработке — от документов, удостоверяющих личность, и регистрационных форм до банковских выписок и подтверждения адреса», — добавил эксперт.