











Агент искусственного интеллекта (ИИ-агент, AI agent) — это автономная программная единица, которая часто используется для дополнения большой языковой модели (LLM). Об их особенностях и способах применения на портале The New Stack рассказывает Джунэйд Али, британский специалист в области управления программной инженерией, компьютерной безопасности и распределенных систем.
По мере того как LLM становятся все более мощными, развивается новая разновидность ПО, известная как «агенты», которые дополняют и расширяют возможности LLM. В этой статье мы расскажем об их ключевых особенностях и о том, как они дополняют LLM.
С момента выхода первого релиза ChatGPT, основанного на GPT 3.5, LLM развивались и совершенствовались. Некоторые из последних релизов, такие как GPT-4o, Gemini Pro и Claude Opus, даже продемонстрировали продвинутые способности к рассуждениям. В последнее время быстро развивается и ландшафт открытых языковых моделей. Было выпущено несколько вариантов таких LLM для использования в частных средах. В плане рассуждений и ответов на сложные вопросы некоторые открытые языковые модели, такие как Mistral и Llama 3, не уступают коммерческим моделям. Все это послужило стимулом для развития направления ИИ-агентов.
Что такое ИИ-агент?
Агент — это автономный программный объект, который использует возможности LLM по обработке языка для выполнения широкого спектра задач, выходящих за рамки простого создания и понимания текста. Эти агенты расширяют функциональность LLM за счет включения механизмов взаимодействия с цифровой средой, принятия решений и выполнения действий на основе понимания языка, полученного от LLM.
Агенты в значительной степени полагаются на LLM для выполнения рассуждений, расширяя при этом функциональность LLM за счет добавления новых возможностей.
У LLM есть несколько ограничений, которые пытаются преодолеть с помощью агентов. Давайте рассмотрим некоторые из них.
Ограничения LLM
У LLM нет памяти
Подобно вызову REST API, обращение к LLM не сохраняет состояние (stateless). Каждое взаимодействие с LLM является независимым, то есть модель по своей природе не запоминает предыдущие обмены и не опирается на предыдущие разговоры. Это ограничение влияет на непрерывность и согласованность долгосрочных взаимодействий, так как модель не может использовать исторический контекст для обоснования будущих ответов. Stateless-природа LLM требует, чтобы каждый ввод был полностью автономным, что приводит к повторяющимся или разрозненным взаимодействиям в расширенных сценариях использования.
Синхронность вызовов LLM
LLM работают синхронно, то есть они обрабатывают и отвечают на каждый ввод последовательно, по одному за раз. Такая синхронная работа подразумевает, что модель должна завершить свой ответ на полученный запрос, прежде чем обрабатывать следующий. Такая последовательная обработка может стать ограничением в сценариях, требующих взаимодействия в реальном времени или одновременной обработки нескольких запросов, так как она не позволяет распараллелить обработку различных вводов.
LLM могут галлюцинировать
LLM могут создавать галлюцинации — случаи, когда модель генерирует фактологически неверную или нелепую информацию. Это явление происходит потому, что LLM обучаются на огромных массивах данных, состоящих из текстов из Интернета, где они изучают шаблоны и корреляции, а не фактическую точность. В результате они могут выдумывать детали или уверенно представлять ложную информацию, создавая иллюзию знания.
LLM не могут выходить в Интернет
LLM не могут просматривать веб-страницы или вызывать веб-службы, поэтому они ограничены данными, на которых их обучали, и не имеют возможности получать или проверять информацию из живых веб-источников в режиме реального времени. Это ограничение означает, что их ответы основаны исключительно на уже заложенных в них знаниях, которые могут быть неактуальными или контекстуально нерелевантными для запросов в реальном времени. Следовательно, LLM не могут предоставить актуальные новости, доступ к последним исследованиям или извлечь данные из динамических онлайновых баз данных, что делает их использование менее эффективным для задач, требующих самой свежей информации.
LLM плохо разбираются в математике
LLM часто плохо справляются с математическими задачами, особенно с теми, которые требуют точных вычислений или решения сложных проблем. Это ограничение возникает потому, что LLM в первую очередь предназначены для понимания и генерирования на естественном языке на основе паттернов, полученных из обширных массивов текстовых данных. Хотя они могут выполнять простые арифметические действия и следовать основным математическим правилам, их способность решать более сложные математические задачи или обеспечивать точность в многоэтапных вычислениях ограничена. Им часто не хватает структурированного логического мышления, необходимого для надежного выполнения сложных математических операций.
У LLM недетерминированный вывод
LLM демонстрируют недетерминированный вывод с точки зрения формата и структуры данных, что означает, что идентичные входные данные могут давать различные выводы при каждой обработке. Эта вариативность обусловлена вероятностной природой алгоритмов, лежащих в основе LLM, которые выбирают из ряда возможных ответов, основываясь на выученных шаблонах, а не на детерминированных правилах. В результате формат и структура выходных данных могут отличаться, что затрудняет достижение согласованных результатов, особенно в приложениях, требующих единообразия в форматировании ответов, таких как автоматическое создание отчетов, заполнение форм или извлечение данных.
Как агенты дополняют LLM?
Агенты устраняют разрыв между традиционными инструментами разработки ПО и LLM, что позволяет устранить или смягчить некоторые из вышеперечисленных ограничений.
Например, благодаря интеграции таких инструментов, как веб-браузеры и среды выполнения кода, агенты могут комбинировать реальные данные со сложными расчетами, прежде чем обратиться к LLM с запросом проанализировать их и подготовить подробный ответ.
В контексте операционных систем считайте, что LLM — это ядро, а агенты — программы. Оболочка состоит из инструментов и вспомогательных служб, необходимых агентам. Агенты расширяют функциональность LLM, связывая его с инструментами и внешними сервисами, необходимыми для выполнения задачи.
Давайте разберемся, какую роль играют агенты в расширении возможностей LLM.
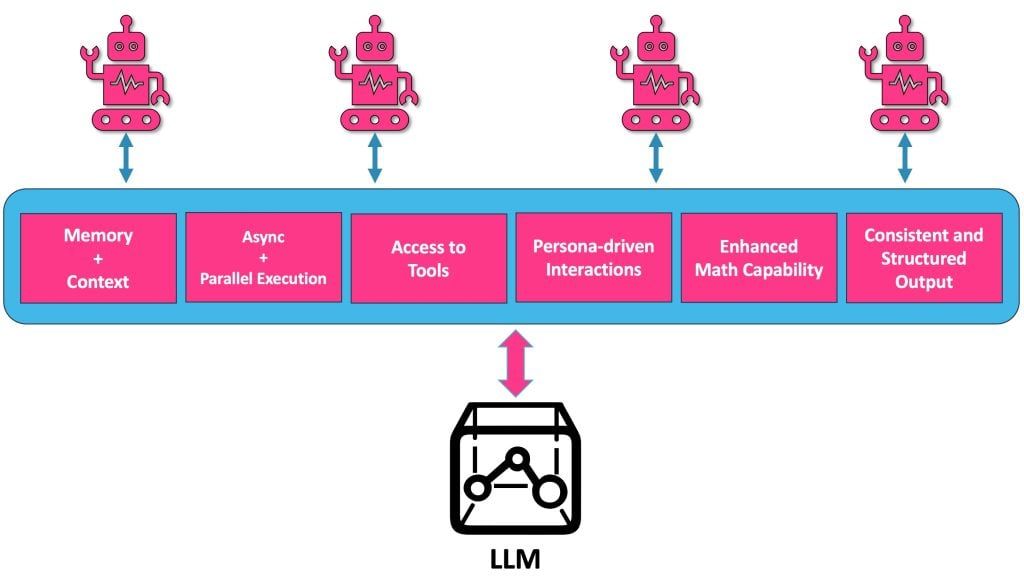
Память и сохранение контекста
В отличие от LLM, которые являются stateless и не сохраняют память о предыдущих взаимодействиях, агенты могут использовать механизмы памяти для запоминания прошлых взаимодействий и действий на их основе. Это позволяет агентам поддерживать непрерывность и согласованность в долгосрочных взаимодействиях, используя исторический контекст для обоснования будущих ответов. Такая возможность улучшает пользовательский опыт, создавая более персонализированные и контекстуально релевантные взаимодействия.
Асинхронная и параллельная обработка
В то время как LLM обрабатывают входные данные синхронно и последовательно, агенты могут управлять несколькими задачами одновременно и работать асинхронно. Такая возможность распараллеливания процессов позволяет агентам более эффективно управлять взаимодействием в режиме реального времени, повышая эффективность и скорость реагирования в сценариях, требующих одновременной обработки нескольких запросов или задач.
Проверка фактов и доступ к информации в режиме реального времени
Агенты могут смягчить проблему галлюцинаций в LLM, включив проверку данных в реальном времени и доступ к внешним источникам информации. Подключаясь к Интернету или специальным базам данных, агенты могут проверять информацию, генерируемую LLM, обеспечивая точность и уменьшая количество ложных или вводящих в заблуждение результатов. Это делает агентов особенно ценными в приложениях, где актуальная и точная информация имеет решающее значение.
Расширенные математические возможности
Агенты могут интегрировать специализированные математические механизмы или ПО для выполнения сложных вычислений и решения задач, компенсируя математические недостатки LLM. Такая интеграция позволяет агентам выполнять точные и надежные математические операции, что расширяет их возможности в технических и научных областях.
Согласованное форматирование выходных данных
Чтобы решить проблему недетерминированного характера результатов LLM, агенты могут реализовать шаги по пост-обработке, чтобы стандартизировать формат и структуру ответов. Например, они могут обеспечить, чтобы выходные данные LLM всегда были отформатированы в JSON или XML. Обеспечивая согласованность в представлении данных, агенты могут повысить надежность выходных данных в приложениях, требующих единообразия, таких как создание отчетов и извлечение данных.
Взаимодействие, ориентированное на персон
Агенты улучшают взаимодействие с LLM на основе персон, используя память и возможности персонализации для создания более индивидуального и привлекательного пользовательского опыта. Сохраняя контекст в течение нескольких взаимодействий, агенты могут адаптировать ответы в соответствии с предпочтениями пользователя, его историей и стилем общения — эффективно моделируя целостную персону. Такой персонализированный подход не только повышает удовлетворенность пользователей, но и позволяет агентам оказывать более релевантную и учитывающую контекст помощь. Агенты могут динамически корректировать свое поведение на основе обратной связи с пользователем и его прошлых взаимодействий, что делает разговор более естественным и похожим на человеческий.
Резюме
LLM значительно эволюционировали, примером чему служат такие модели, как GPT-4o и Gemini 1.5. Однако они по-прежнему не сохраняют состояние, обрабатывают входные данные последовательно, могут галлюцинировать, не имеют доступа к данным реального времени, испытывают трудности со сложными математическими вычислениями и выдают недетерминированные результаты.
ИИ-агенты расширяют возможности LLM, внедряя механизмы памяти для сохранения контекста, асинхронного управления задачами и проверки информации в реальном времени, что повышает точность и согласованность. Они также интегрируют специализированные математические механизмы и стандартизируют форматы вывода, что делает их более надежными и эффективными для различных приложений.













