Федеративные языковые модели (Federated Language Models, FLM) — это идея, которая использует преимущества двух тенденций развития генеративного ИИ: расширение применения малых языковых моделей (SLM) и рост возможностей больших языковых моделей (LLM), пишет на портале The New Stack Джанакирам МСВ, главный аналитик компании Janakiram & Associates.
В области генеративного ИИ произошли два значительных события: появление SLM, которые могут работать на устройствах, и расширение возможностей выполняемых в облаке LLM с точки зрения размера контекста, интеграции инструментов, мультимодальности и сложных рассуждений. FLM используют преимущества этих двух тенденций, позволяя при этом предприятиям соблюдать конфиденциальность, приватность и безопасность.
При использовании FLM мы имеем дело с двумя языковыми моделями — SLM, работающей на периферии, и LLM, работающей в облаке. SLM используется в основном для генерации, а LLM — для сопоставления запроса с набором подходящих инструментов и связанных с ними параметров. На приведенной ниже схеме показаны архитектура и потоки при использовании модели FLM.
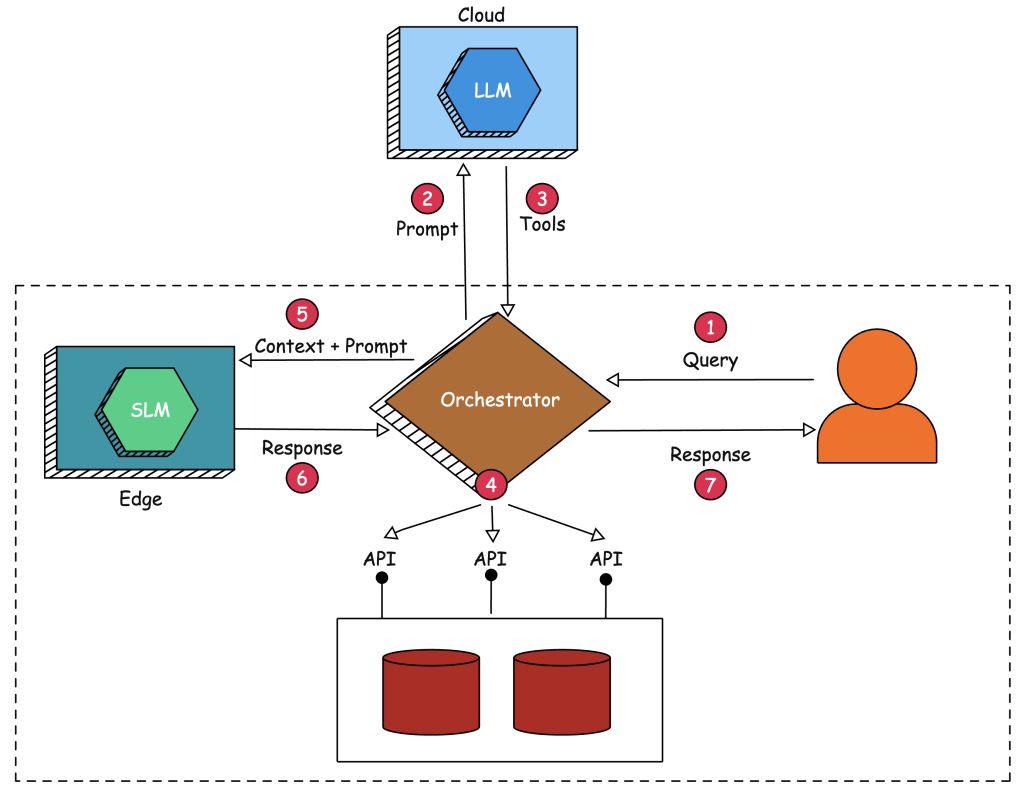
Цель состоит в том, чтобы реализовать агент Retrieval Augmented Generation (RAG, генерация с расширенным поиском) без необходимости передачи конфиденциального контекста мощным LLM, работающим в открытом доступе. LLM используется для сопоставления запроса с подходящими инструментами, имеющими доступ к конфиденциальным внутренним данным и приложениям. Приложение, оркестрирующее обращение к языковым моделям, запускает инструменты, определенные LLM, для извлечения контекста, который отправляется менее мощной SLM, работающей локально на недорогом периферийном устройстве. Такая архитектура позволяет скрыть конфиденциальные данные от LLM, делегировав фактическую генерацию SLM.
Прежде чем мы рассмотрим реализацию этой архитектуры, давайте остановимся на некоторых последних тенденциях в развитии языковых моделей.
Особенности развития LM
1. SLM становятся все более работоспособными и зрелыми
SLM демонстрируют значительный прогресс в производительности и эффективности. Недавние разработки, такие как Gemini Nano от Google DeepMind и Microsoft Phi-3, служат примером этой тенденции.
Gemini Nano предназначена для эффективной работы на периферийных устройствах, обеспечивая мощные возможности обработки языка без необходимости использования больших вычислительных ресурсов. Аналогичным образом, Phi-3 использует инновационную архитектуру и методы обучения для обеспечения высокой точности и контекстуального понимания в компактном виде. Эти модели, а также другие в категории SLM, демонстрируют расширенные возможности понимания, генерации и перевода естественного языка, что делает их подходящими для широкого спектра приложений — от мобильных устройств до корпоративных решений.
Прогресс в области SLM свидетельствует о переходе к более доступным и универсальным решениям в области ИИ, отражая более широкую тенденцию оптимизации моделей ИИ для повышения эффективности и практического применения на различных платформах.
2. Вызов функций и интеграция инструментов по-прежнему удел LLM
Вызов функций и инструменты по-прежнему ограничиваются преимущественно LLM, поскольку SLM не обладают необходимыми возможностями для выполнения этих сложных задач.
LLM, такие как OpenAI GPT-4o, Anthropic Claude 3.5 Sonnet и Google Gemini 1.5 Pro, обладают широкими возможностями контекстного понимания и рассуждений, что позволяет им обрабатывать сложные вызовы функций и легко интегрироваться с различными инструментами. В отличие от них, SLM, несмотря на растущую сложность, все еще ограничены меньшим количеством параметров и ограниченными вычислительными возможностями. Это мешает им обрабатывать сложные инструкции и эффективно взаимодействовать с внешними системами.
Хотя такие модели, как Gemini Nano и Phi-3, добились успехов в повышении эффективности и точности SLM, они все еще не справляются с выполнением расширенных функций и интеграцией инструментов, которые требуют надежной работы и обширных обучающих данных, характерных для LLM. В результате использование вызова функций и сложного взаимодействия с инструментами по-прежнему остается областью, в которой доминируют LLM.
3. LLM не могут быть развернуты на периферийных устройствах, таких как Nvidia Jetson
Языковые модели не могут быть эффективно развернуты на периферийных устройствах, таких как Nvidia Jetson, из-за присущих им ограничений на вычислительные ресурсы и проблем, связанных с квантованием. Хотя квантование LLM для уменьшения их размера и вычислительных требований является распространенным подходом, оно часто приводит к значительной потере точности и возможностей. Такие квантованные модели не могут поддерживать тот же уровень точности и контекстуального понимания, что и их полноразмерные аналоги, что приводит к снижению производительности в задачах, требующих глубокого понимания языка.
Кроме того, памяти и вычислительной мощности периферийных устройств, таких как Nvidia Jetson, недостаточно, чтобы справиться со сложностью LLM, даже в квантованном виде. В результате развертывание LLM на этих устройствах остается нецелесообразным, поскольку компромисс в производительности и точности перевешивает преимущества. Это ограничение подчеркивает необходимость дальнейшей разработки более эффективных моделей и алгоритмов, которые могли бы сбалансировать требования расширенной обработки языка с ограничениями периферийных вычислительных сред.
4. Бóльшая часть конфиденциальных данных, необходимых для RAG, заперта в дата-центре
Размещение таких данных в защищенных дата-центрах подчеркивает значительные проблемы с соблюдением нормативных требований и безопасностью, связанные с отправкой этих данных в LLM, работающие в открытом доступе.
Передача конфиденциальных данных внешним LLM может нарушить строгие правила соответствия, такие как GDPR и HIPAA, которые предусматривают строгий контроль доступа к данным и их обработки. Кроме того, существует риск, что эта конфиденциальная информация может быть непреднамеренно использована на этапах предварительного обучения и тонкой настройки LLM, что приведет к потенциальной утечке данных или их несанкционированному использованию. Кроме того, задержка при передаче локальных данных в облачные LLM может существенно повлиять на производительность и скорость отклика, что сделает приложения реального времени менее жизнеспособными.
Эти проблемы усугубляются отсутствием контроля над данными после того, как они покидают защищенную среду дата-центра, что повышает уязвимость к киберугрозам и неправомерному использованию. Поэтому организации должны уделять первоочередное внимание хранению конфиденциальных данных в своей защищенной инфраструктуре, используя для RAG локальные или частные облачные решения, чтобы обеспечить соответствие требованиям и снизить риски, связанные с конфиденциальностью и безопасностью данных.
5. Агентные рабочие процессы опираются на более чем одну языковую модель
Агентные рабочие процессы, в которых участвуют автономные агенты, выполняющие сложные задачи с помощью ряда взаимозависимых шагов, для достижения оптимальных результатов опираются на несколько языковых моделей.
Агентный рабочий процесс призван имитировать решение проблем, подобное человеческому, путем разбиения задач на более мелкие, управляемые компоненты и их последовательного или параллельного выполнения. Это часто приводит к необходимости использования нескольких специализированных языковых моделей, каждая из которых предназначена для работы с определенными аспектами рабочего процесса. Например, одна модель может отлично понимать естественный язык, другая — генерировать подробные ответы, а третья — обрабатывать знания, специфичные для конкретной области.
Кроме того, агенты могут опираться на SLM на периферии для обработки данных в реальном времени с низкой задержкой и на более мощные LLM в облаке для решения сложных ресурсоемких задач. Используя уникальные возможности различных моделей, агентные рабочие процессы могут обеспечить более высокую точность, эффективность и контекстную релевантность своих операций. Необходимость взаимодействия с несколькими моделями позволяет рабочему процессу интегрировать различные возможности, обеспечивая целостное и эффективное решение сложных задач, а не полагаться на ограниченные возможности одной модели. Такой мультимодельный подход имеет решающее значение для достижения тонких и сложных результатов, ожидаемых от агентных рабочих процессов в реальных приложениях.
Реализация FLM
Шаг 1. Пользователь отправляет запрос, требующий доступа к локальным базам данных, открываемым агенту в виде API.
Шаг 2. Поскольку SLM, работающая на периферии, не может сопоставить запрос с функциями и аргументами, агент, который выступает в роли оркестратора и связующего звена, отправляет запрос вместе с доступными инструментами LLM, работающей в облаке.
Шаг 3. Мощная LLM отвечает оркестратору набором инструментов — функций и аргументов. Единственная задача этой модели, работающей в открытом доступе, — разбить запрос на список функций.
Шаг 4. Агент запускает инструменты, определенные LLM, и выполняет их параллельно. По сути, это означает вызов API, взаимодействующего с локальными базами и источниками данных, которые являются конфиденциальными и секретными. Агент агрегирует ответы от вызванных функций и создает контекст.
Шаг 5. Затем агент отправляет исходный запрос, отправленный пользователем, вместе с агрегированным контекстом, собранным с помощью инструментов, в SLM, работающую на периферии.
Шаг 6. SLM отвечает фактической информацией, полученной из контекста, отправленного оркестрантом/агентом. Она, очевидно, ограничена размером контекста, поддерживаемого SLM.
Шаг 7. Агент отправляет окончательный ответ на исходный запрос, отправленный пользователем.
Проблемы, связанные с FLM
Несмотря на перспективность этого подхода, он может столкнуться с проблемами реализации:
- Необходимо тщательно управлять координацией между периферийной SLM и облачной LLM.
- Производительность SLM для задач генерации может не соответствовать производительности LLM, что потенциально ограничивает общие возможности системы.
- Подход может вносить задержки из-за обмена данными между периферией и облаком.
Заключение
Цель данной статьи — представить FLM, инновационный подход, объединяющий периферийные SLM с облачными LLM. Этот подход использует LLM для планирования сложных задач, а SLM — для генерации локальных данных, что позволяет решить проблемы конфиденциальности в корпоративных ИИ-приложениях. Несмотря на перспективность, система сталкивается с проблемами координации между моделями, потенциальными ограничениями производительности SLM и проблемами задержки. Тем не менее система предлагает новое решение, балансирующее между расширенными возможностями ИИ и безопасностью данных, хотя для успеха очень важна тщательная реализация.