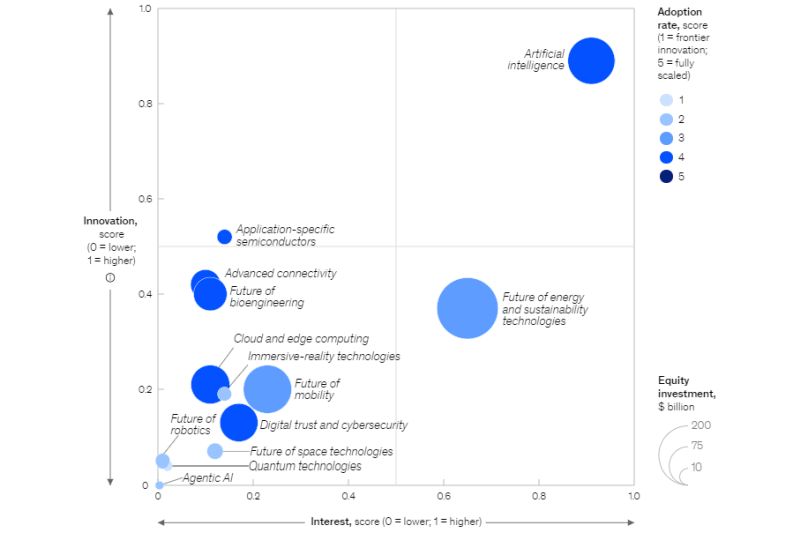




Выполнение процессов машинного обучения и взаимодействия с пользователями на периферии (edge) может обеспечить реализацию искусственного интеллекта на мобильных устройствах, пишет на портале AI Business Мохан Вартакави, вице-президент Couchbase по разработке ПО, ИИ и периферии.
Предприятия все еще исследуют потенциал генеративного ИИ (GenAI) и больших языковых моделей (LLM). Но это не значит, что они уже не смотрят на следующий рубеж. Для многих настоящий мобильный ИИ — это святой Грааль, открывающий устройствам возможности, традиционно предоставляемые приложениями, требовательными к энергии и ресурсам.
Речь идет не только о смартфонах или других устройствах — хотя потребительские и бизнес-приложения, безусловно, будут рассматривать их в качестве цели. Это также означает расширение присутствия GenAI в Интернете вещей (IoT), что может привести к созданию действительно интеллектуальных операционных систем.
Вопрос в том, как этого добиться. Современные мобильные устройства далеко ушли от Nokia 3210, но даже этого экспоненциального скачка недостаточно для использования преимуществ LLM. И если вычислительная мощность не является решением проблемы, то что же тогда?
Создание правильной архитектуры
Можно предположить, что мобильный ИИ может существовать только в облаке, где центральные серверы выполняют тяжелую обработку, а устройство лишь отображает результаты. Однако для того, чтобы добиться успеха, настоящий мобильный ИИ должен разорвать ограничения, которые делают облако незаменимым. Подключение, безусловно, является проблемой — приложение, которое не работает, если оно не может подключиться к облаку, сразу же теряет свою ценность. Но есть также вопросы эффективности, скорости и конфиденциальности данных.
Лучшие приложения GenAI работают как можно ближе к реальному времени. Каждая секунда задержки означает снижение актуальности данных, замедление реакции и снижение достоверности выводов, к которым приходит ИИ. Задержки, связанные с передачей данных на центральный сервер и обратно, означают, что облачный подход всегда будет страдать недостатками. К тому же организациям приходится бороться с расходами на пропускную способность канала связи, связанными с постоянной передачей данных, а также с риском компрометации данных, находящихся в пути. Очевидно, что чем больше можно реализовать на самом устройстве, тем лучше.
Это не значит, что облачные серверы не имеют значения. Задачи с высокими вычислительными требованиями, с которыми мобильное устройство никогда не справится, — например, обучение LLM и моделей глубокого обучения — по-прежнему лучше всего подходит для облачных серверов. Однако процессы МО и любые задачи, требующие немедленного взаимодействия между пользователями и самим ИИ, должны происходить на устройстве, находящемся на периферии сети. Это означает необходимость снижения вычислительной нагрузки на устройство и обеспечение архитектуры, построенной с учетом специфических требований периферийных вычислений.
Снижение нагрузки на устройства
Перекладывание самой тяжелой вычислительной нагрузки на облако поможет сделать настоящий мобильный ИИ более доступным. Но для того чтобы мобильные устройства могли запускать приложения GenAI на необходимом уровне производительности, эту нагрузку необходимо снизить.
В конечном итоге наибольшую нагрузку создает сама модель ИИ. Чем больше ее можно упростить — например, снизить точность вычислений до приемлемых параметров, — тем меньше нагрузка на устройство. Аналогичным образом, оптимизация операций в других местах для повышения эффективности позволит устройству выделить максимум ресурсов для своих приложений GenAI.
Точный подход зависит от конкретных потребностей каждого приложения. Но квантование модели, как правило, является важным шагом на пути к упрощению модели ИИ до уровня, достаточного для эффективной работы. Кроме того, такие подходы, как GPTQ, который сжимает модели после обучения; LoRA, который точно настраивает небольшие матрицы в предварительно обученной модели; и QLoRA, который оптимизирует использование памяти GPU для повышения эффективности, могут еще больше снизить нагрузку и сделать настоящий мобильный ИИ более доступным.
Управление данными
Наконец, как и любое другое приложение, ИИ требует тщательного управления данными. Во-первых, данные должны быть конфиденциальными и защищенными. Внедрение методов, обеспечивающих конфиденциальность, таких как предотвращение передачи данных с устройства на обучаемую LLM и дополнение их шифрованием, чтобы данные были защищены, даже если случится худшее, должно стать приоритетом.
Во-вторых, данные должны быть согласованы по всей сети. Для обеспечения целостности критически важна синхронизация данных между периферийными устройствами и облачными или центральными серверами. При ее наличии организация будет уверена, что ее ИИ работает на каждом устройстве на основе одних и тех же данных, поэтому он не придет к неожиданным или даже опасным выводам.
В этих условиях консолидированная платформа данных, способная управлять различными типами данных и предоставлять моделям ИИ доступ к локальным хранилищам данных, станет значительным преимуществом. Платформа данных, обеспечивающая доступ к данным в автономном или онлайн-режиме, повышающая производительность и улучшающая пользовательский опыт, также будет важным преимуществом. При наличии правильной платформы приложения ИИ смогут работать в самых разных средах, гарантируя быстроту реакции и надежность, что позволит получить гораздо более ценный инструмент.
Золотое правило
В конечном счете управление данными и архитектура возвращаются к золотому правилу, лежащему в основе многих ИТ-стратегий: все должно быть просто. Чем больше организации смогут минимизировать сложность, тем больше сил и внимания они смогут уделить самому ИИ. В мобильной среде, где на счету каждая капля вычислительных мощностей, это очень важно для успеха.