
Визуально-языковые модели (Vision Language Models, VLM) могут использоваться в широком спектре приложений, требующих синтеза визуальной и текстовой информации, сообщает портал The New Stack.
Недавнее появление мультимодального искусственного интеллекта означает, что системы ИИ становятся все более многоцелевыми по своей природе, поскольку они одновременно обрабатывают и генерируют различные модальности данных — включая текст, изображения, аудио и видео — в интегрированном виде.
Одним из наиболее универсальных подмножеств мультимодального ИИ являются VLM, которые объединяют возможности обработки естественного языка (NLP) и компьютерного зрения (CV) для решения продвинутых визуально-языковых задач — таких, как создание текстовых описаний изображений, ответы на вопросы по изображениям, поиск и генерация изображения по тексту.
Архитектура визуально-языковых моделей
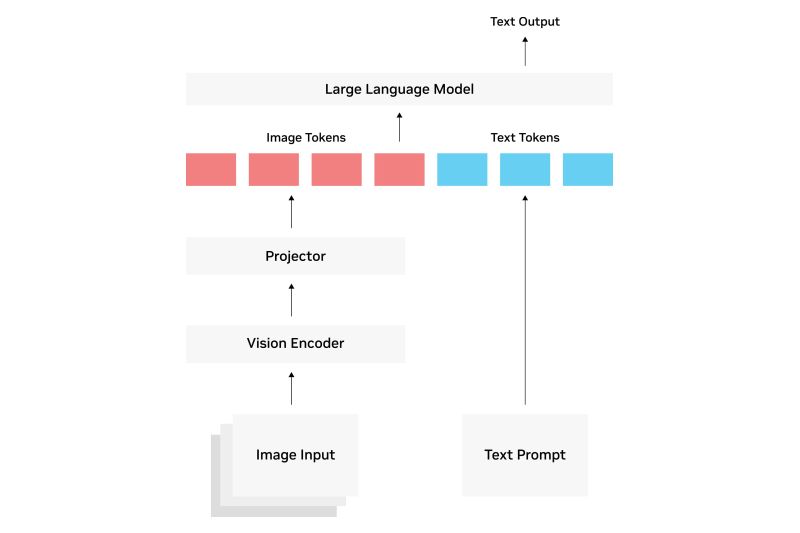
VLM способны обрабатывать как текстовые, так и графические данные, при этом часть модели, связанная с компьютерным зрением, анализирует и интерпретирует визуальные данные, а часть модели, связанная с обработкой естественного языка, анализирует и понимает текст. В некотором смысле, можно представить VLM как поливалентные большие языковые модели (LLM), способные понимать как слова, так и изображения.
В целом, VLM состоят из следующих основных компонентов:
- Визуальный кодировщик. Эта часть извлекает визуальные сигналы, такие как формы, узоры и цвета, из визуальных данных и преобразует их в векторные вложения — числовые представления точек данных в высокоразмерном пространстве, — которые могут быть поняты моделью ИИ. В прошлом VLM использовали для извлечения признаков из изображений сверточные нейронные сети. В настоящее время многие VLM обычно используют визуальный трансформер (ViT), который делит изображение на «пятна» фиксированного размера и затем обрабатывает их как лексемы, подобно тому, как языковая модель на основе трансформера разбирает слова в предложении.
- Языковый кодировщик. Этот компонент оценивает семантическое значение и контекстуальные ассоциации между словами и преобразует эту информацию в текстовые вложения.
- Проектор/механизм слияния. Этот важный элемент объединяет вложения признаков, полученные от визуального и языкового кодировщиков, в общее мультимодальное пространство.
- Мультимодальный трансформер. Этот интегрированный компонент, работающий над объединенными визуальными и языковыми вложениями, часто использует механизм самовнимания в рамках модальностей, который оценивает контекстуальную важность слов в последовательности, позволяя модели предсказать наиболее вероятный порядок слов в предложении. Кроме того, он использует механизм перекрестного внимания между модальностями для изучения отношений между изображениями и словами, а также позиционное кодирование для сохранения контекстуальности между фрагментами изображений и текстовыми лексемами.
- Компоненты («насадки») для конкретных задач. Они адаптируют конечные результаты к конкретным задачам, для выполнения которых была разработана модель. Примерами специфичных для конкретной задачи «насадок» являются классификация, генерация и ответы на вопросы.
")
Методы обучения VLM
Стратегии обучения VLM часто включают в себя сочетание методов, которые помогают выровнять и объединить данные, полученные от визуальных и языковых компонентов.
- Контрастное обучение. Этот подход обучает модель различать схожие и несхожие пары точек данных путем отображения вложений изображений и текста в общее пространство вложений. По мере обучения модели на наборах данных, состоящих из парных изображений и текста, она генерирует оценку сходства. Затем она учится минимизировать расстояние между совпадающими парами вложений и максимизировать расстояние между несовпадающими. Одним из примеров контрастной модели является CLIP, которая использует для выполнения прогнозов трехэтапный процесс с обучением без примеров.
- PrefixLM. Это NLP-метод для предварительного обучения языковых моделей, в котором часть текста (т. е. префикс) используется в качестве входных данных, а модель учится предсказывать следующую часть в последовательности. В VLM метод PrefixLM часто используется в сочетании с упрощенной архитектурой SimVLM (Simple Visual Language Model) для обеспечения возможности обучения без примеров, что позволяет модели эффективно предсказывать следующую последовательность текста на основе изображения и связанного с ним текстового префикса, а также с помощью визуального трансформера.
- Frozen PrefixLM. Этот метод обучения основан на PrefixLM, но параметры языковой модели замораживаются во время обучения, что приводит к более эффективному с вычислительной точки зрения процессу обучения.
- Маскированное моделирование. При таком подходе части текста или изображения случайным образом затемняются. Затем VLM учится предсказывать и «заполнять» недостающие части маскированного ввода, либо используя маскированное языковое моделирование для создания недостающей текстовой информации при получении незамаскированного изображения, либо используя маскированное визуальное моделирование для восстановления недостающих пикселов изображения при получении незамаскированной текстовой надписи. FLAVA (Foundational Language And Vision Alignment) — один из примеров модели, в которой используется такая техника маскирования, а также контрастное обучение.
- Генеративное обучение модели. В этом методе VLM обучается выдавать новые результаты в зависимости от полученного текста и изображения. Это может означать генерацию изображений на основе текстовых данных (текст в изображение) или текстовых описаний или резюме, связанных с изображением (изображение в текст). Примерами генеративных VLM, преобразующих текст в изображение на основе диффузии являются Midjourney и Stable Diffusion.
- Предварительное обучение модели. Чтобы сократить расходы и время на обучение VLM с нуля, можно построить модель на основе предварительно обученных LLM и визуальных кодировщиков, добавив дополнительные сетевые слои отображения для согласования изображений и текста. Дистилляция знаний — одна из техник, которая может быть использована для передачи знаний от предварительно обученной модели «учитель» к более простой и легкой модели «ученик». Кроме того, можно адаптировать и точно настроить существующую VLM для конкретного приложения с помощью таких инструментов, как Transformers и SFTTrainer.
Как можно использовать VLM
VLM могут использоваться в широком спектре приложений, требующих синтеза визуальной и текстовой информации, в том числе:
- генерация изображений;
- генерация текстовых описаний изображений и их обобщение;
- сегментация изображений;
- поиск изображений;
- обнаружение объектов;
- понимание видео;
- ответы на вопросы об изображении (VQA);
- извлечение текста для интеллектуального понимания документов;
- модерация и безопасность онлайн-контента;
- поддержка интерактивных систем, например, в образовании и здравоохранении;
- телемедицина, автоматизированные диагностические инструменты и виртуальные помощники.
Заключение
VLM — это лишь один из подтипов растущего числа универсальных и мощных мультимодальных моделей ИИ, которые появляются в настоящее время. И надо понимать, что, как и при разработке и внедрении любой модели ИИ, здесь есть проблемы, связанные с потенциальной необъективностью, стоимостью, сложностью и галлюцинациями.