











Хотя идея «озера-хранилища данных» (data lakehouse) привлекательна, на данный момент она выглядит скорее мечтой, чем реальностью, пишут на портале Datanami представители инвестиционного фонда Cota — старший юрист инвестиционной команды Эрик Ли и партнер и технический директор Рич Эллинджер.
Хранилища данных (data warehouses) и озера данных (data lakes) служат четким и разным целям. Как правило, в хранилищах данных хранятся структурированные данные в соответствии с заранее определенной схемой, что позволяет быстро выполнять запросы для создания отчетов. Озера данных, с другой стороны, хранят и обрабатывают различные типы данных, включая неструктурированные, и поддерживают расширенную аналитику, обнаружение данных, а также рабочие нагрузки искусственного интеллекта и машинного обучения.
Появившаяся недавно концепция озера-хранилища объединяет лучшее из двух этих миров.
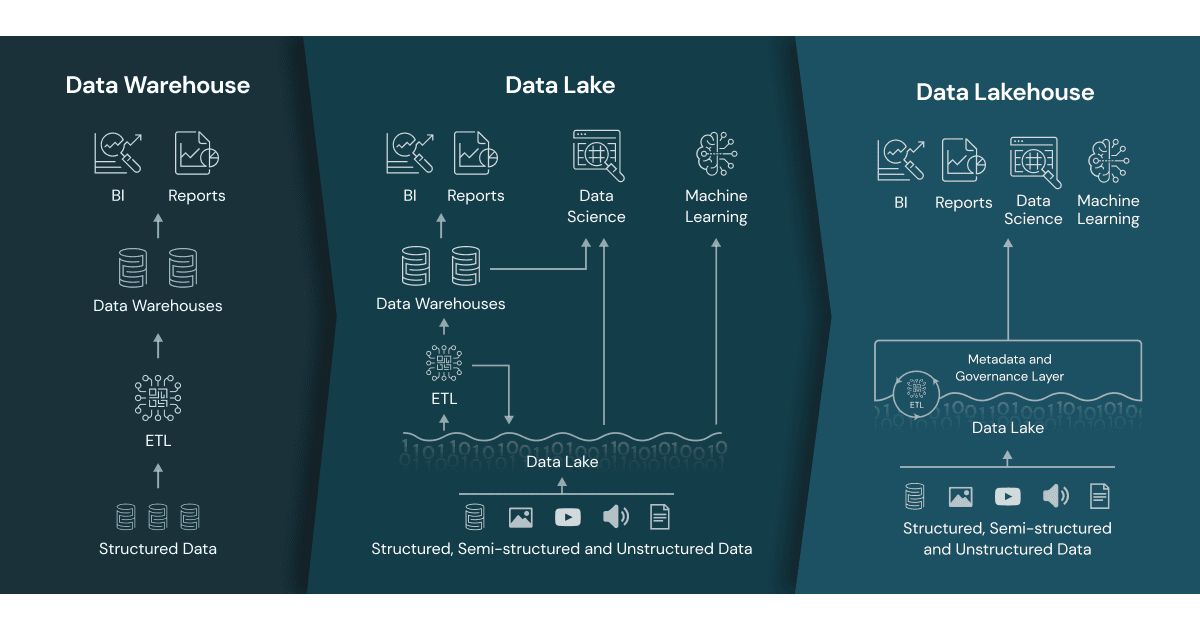
Теоретически озеро-хранилище данных избавляет от необходимости использовать две отдельные системы для хранения и анализа данных. Оно объединяет их, избавляя от необходимости перемещать данные между системами и позволяя беспрепятственно выполнять запросы ко всем наборам данных. Кроме того, поскольку компании стремятся использовать преимущества ИИ, озеро-хранилище может предоставить моделям ИИ единый источник истины и более полное представление о данных. Озеро-хранилище также позволит сократить расходы. Сегодня корпоративные клиенты жалуются, что расходы резко растут, поскольку им приходится платить огромные деньги за использование как хранилищ данных, так и озер данных.
Естественно, такие поставщики, как Snowflake (лидер в области хранилищ данных) и Databricks (лидер в области озер данных), стремятся выйти на быстрорастущие рынки друг друга, и конкуренция только усиливается, поскольку компании борются за рабочие нагрузки ИИ/МО. Ожидается, что в период с 2022 по 2026 гг. совокупный рост этих секторов составит 25% в год, что в 1,7 раза превышает темпы роста всего рынка аналитики данных. При ожидаемых темпах роста объединенный рынок могут стать крупнейшим сегментом в аналитике данных, расходы на который превысят расходы на реляционные и нереляционные базы данных. Уже сейчас обе эти компании активно разрабатывают продукты и технологии для расширения возможностей и продвижения в основную сферу деятельности друг друга в своем стремлении создать озеро-хранилище данных. Мы пока они этого не достигли.
Хотя идея озера-хранилища привлекательна, на данный момент она выглядит скорее мечтой, чем реальностью. Да, сочетание скорости выполнения запросов в хранилищах данных с гибкостью структуры данных в озерах данных стало бы революционным событием. Однако проблема заключается в том, что их базовые архитектуры структурно различны.
Были предприняты усилия, чтобы обеспечить переход от озер данных к озерам-хранилищам данных путем разработки специальных технологий. Одна из таких разработок включает в себя создание новых механизмов запросов, которые способствуют высокопроизводительному выполнению SQL в озерах данных. Эти ускорители запросов создают программный уровень над открытыми форматами таблиц, такими как Delta Lake, Apache Hudi и Apache Iceberg, и обеспечивают повышенную производительность, приближающуюся к скорости выполнения запросов в хранилищах данных.
Однако ограничением этих ускорителей запросов является их склонность к сбоям под нагрузкой тысяч одновременных пользователей, пытающихся получить доступ к одним и тем же данным. Эта проблема масштабируемости может препятствовать их широкому распространению и использованию в крупномасштабных корпоративных сценариях. Таким образом, хотя эти механизмы запросов могут значительно повысить ценность озер данных, они вряд ли смогут полностью заменить функциональность хранилищ данных.
Хранилища данных, в свою очередь, принимают открытые форматы таблиц, чтобы обеспечить возможности озер данных и облегчить переход к озерам-хранилищам. Например, AWS и Google Cloud используют открытый формат таблиц Apache Iceberg для своих «движков озер данных». Неструктурированные данные они хранят в S3 или Google Cloud Storage, а структурированные — в Redshift или BigQuery.
Snowflake, в свою очередь, пытается устранить необходимость в Databricks, обрабатывая данные Spark непосредственно на своей платформе с помощью Snowpark. Однако реальность такова, что Snowflake еще не достигла функционального паритета с Databricks. В частности, Databricks по-прежнему превосходит ее в основных областях благодаря разработке ускорителей, ориентированных на конкретные сценарии использования.
Еще одним ключевым недостатком концепции озера-хранилища данных является привязка к поставщику. Реальность такова, что большинство компаний не хотят попадать в сильную зависимость от единственного поставщика технологий для хранения, обработки и аналитики данных. Такая зависимость может ограничить гибкость организации в долгосрочной перспективе, поскольку сложно перейти к другим поставщикам без значительных усилий, затрат и потенциальных сбоев в работе.
Кто первым доберется до озера-хранилища?
Несмотря на реальное желание создать озеро-хранилище данных с учетом потенциальных преимуществ единой платформы, нет четкого мнения о том, что — озеро данных или хранилище данных — лучше всего подходит для скорейшей реализации парадигмы озера-хранилища.
Одни считают, что облачные хранилища данных решили самую сложную проблему параллелизма данных, обеспечив одновременный доступ к ним тысячам пользователей. Другие считают, что проще оптимизировать данные, чем гибко их тиражировать, что дает преимущество озерам данных.
Таким образом, хотя концепция data lakehouse остается привлекательной, мы считаем, что в обозримом будущем заказчики будут продолжать использовать технологии озер данных и хранилищ данных параллельно.













