











Предварительно обученные большие языковые модели (LLM), такие как GPT-4 и Gemini, — это прекрасно, но реальные конкурентные преимущества дает сочетание LLM с частными данными, говорится в новом отчете MIT Technology Review. Однако вызывает вопросы то, насколько хорошо компании готовят свои частные данные для генеративного ИИ (GenAI), сообщает портал Datanami.
Несомненно, генеративный ИИ привлекает внимание организаций, которые стремятся использовать LLM для создания чатботов, «вторых пилотов» и других типов приложений. Масштабирование ИИ или GenAI является «главным приоритетом» для 82% руководителей, принявших участие в исследовании «AI readiness for
Согласно результатам опроса, 83% организаций уже определили источники данных, которые они хотят использовать для ИИ или GenAI, и хорошо представляют, какие данные они хотят использовать в GenAI.
Но насколько хорошо организации подготовлены к тому, чтобы на самом деле связать все воедино и предоставить данные приложениям GenAI, когда они нужны и где они нужны, достаточно очищенные и подготовленные, а также в надлежащем формате? И сделать все это, не подвергая опасности конфиденциальность и безопасность?

В этом, конечно, и заключается настоящая хитрость, с которой справляются не многие организации — по крайней мере, пока.
Трудности, связанные с объединением всех инструментов и методов работы с данными, огромны. Как отмечает аналитик IDC Стюарт Бонд, недавнее исследование IDC показало, что среднестатистическая организация имеет «более дюжины различных технологий только для сбора всей информации о своих данных и столько же для их интеграции, преобразования и репликации. Технический долг здесь очень реален».
Старые инструменты интеграции данных и ETL, разработанные для централизованных хранилищ данных, могут не подойти для новых сценариев использования GenAI, говорится в отчете MIT Tech Review. Именно поэтому примечательно, что 82% опрошенных технологических руководителей заявили, что «приоритетом для них является приобретение решений для интеграции и перемещения данных, которые будут работать и в будущем, независимо от других изменений в нашей стратегии работы с данными и партнеров».

Приобретение более совершенных инструментов интеграции данных и ETL/конвейеров данных, безусловно, является приоритетом (64%), но есть и другие важные инвестиции, которые необходимо сделать, говорится в отчете. Так, 35% назвали в качестве приоритетного пункта озера данных, а 31% — инструменты трансформации данных. Вложения в каталоги данных и LLM оказались приоритетом всего для 7% респондентов, а векторные базы данных и вычислительные слои заняли места в середине рейтинга.
Опрошенные технологические руководители указали на множество проблем, связанных с созданием фундамента данных, включая интеграцию данных и создание конвейеров данных, управление данными и безопасность, а также качество данных и другие вопросы.
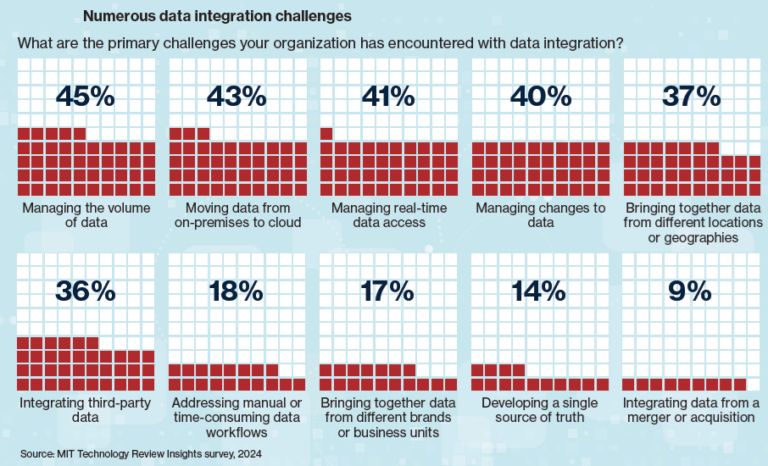
В число четырех задач, с которыми организации больше всего сталкиваются при интеграции данных и построении конвейеров данных, входят управление объемом данных; перенос данных из локальных систем в облако; обеспечение доступа в режиме реального времени; управление изменениями в данных. Интеграция данных из разных географических регионов и интеграция данных третьих сторон также получили значительное количество ответов респондентов.
Генеральный директор Fivetran Джордж Фрейзер согласен с тем, что прочная основа данных является обязательным условием успеха GenAI. «Прежде чем нанимать большое количество специалистов по работе с данными и начинать множество проектов по GenAI, необходимо убедиться, что у вас есть корпоративное хранилище данных с чистыми, контролируемыми данными, которые должны поддерживать все ваши традиционные рабочие нагрузки BI и аналитики, — говорит он. — Если организации не начнут с создания прочного фундамента данных, их специалисты по анализу данных будут транжирить свое время на интеграцию и очистку базовых данных».
Данные опроса становятся немного более нюансированными, когда речь заходит об управлении данными, соблюдении требований и отчетности.
Хотя значительная часть респондентов указала, что самыми серьезными проблемами при подготовке данных для ИИ являются управление и безопасность данных (44% респондентов) и интеграция данных или конвейеры (45%), более глубокое изучение ответов выявляет существенную детализацию.
В частности, исследование показывает, что наибольшие опасения по поводу безопасности и управления в значительной степени проявляются в государственных и финансовых учреждениях — двух крайне консервативных секторах, — в то время как технологические руководители в промышленности, розничной торговле и других отраслях не разделяют эти опасения по поводу безопасности и управления практически в одинаковой степени.
«Организации могут не иметь контроля над тем, что кто-то использует часть данных в бизнес-приложении и отправляет их в модель GenAI, — отмечает Бонд. — Это очень важно».













