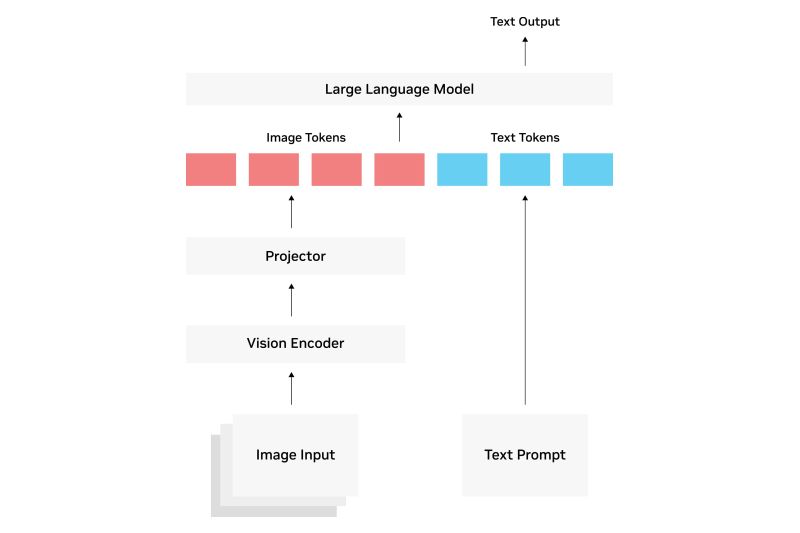



Локальные системы искусственного интеллекта, известные как «LLMs on the edge» (большие языковые модели на периферии), могут помочь снизить нагрузку на дата-центры, но может пройти некоторое время, прежде чем этот подход станет мейнстримом, отмечают опрошенные порталом Data Center Knowledge эксперты.
Проблема, которую представляет собой ИИ для дата-центров, освещается достаточно широко. Одним из способов снизить нагрузку является использование LLM на периферии, то есть позволить системам ИИ работать на ПК, планшетах, ноутбуках, смартфонах и других устройствах.
Очевидные преимущества LLM на периферии включают в себя снижение стоимости обучения LLM, уменьшение задержки при запросах к LLM, повышение конфиденциальности пользователей и надежности. Если такие локальные решения смогут снизить нагрузку на дата-центры за счет уменьшения требований к вычислениям, то смогут устранить необходимость в многогигаваттных ЦОД-фабриках. Но действительно ли такой подход осуществим?
В связи с расширяющейся дискуссией о переносе LLM, лежащих в основе генеративного ИИ (GenAI), на периферию, мы рассмотрим, действительно ли такой перенос может снизить нагрузку на дата-центры.
Смартфоны прокладывают путь периферийному ИИ
Майкл Азофф, главный аналитик практики исследований облачных вычислений и дата-центров компании Omdia, говорит, что наиболее быстро развивающийся сценарий использования ИИ на периферии — это легкие LLM на смартфонах.
Huawei разработала различные варианты размеров своей LLM Pangu 5.0, и самая маленькая версия интегрирована в ОС для смартфонов HarmonyOS. В число устройств, работающих на этой ОС, входит Huawei Mate 30 Pro 5G.
Samsung, тем временем, разработала Gauss LLM, которая используется в Samsung Galaxy AI, работающем на флагманской линейке Galaxy S24. Функции ИИ включают в себя живой перевод, преобразование голоса в текст и резюмирование заметок, поиск по выделенному кругу, а также помощь в работе с фотографиями и сообщениями.
Компания также перешла к массовому производству полупроводников LPDDR5X DRAM. Эти
В целом производители смартфонов прилагают все усилия, чтобы сделать LLM меньше. Вместо 175 млрд. параметров ChatGPT-3 они пытаются обойтись примерно двумя миллиардами.
Intel и AMD тоже занимаются ИИ на периферии. AMD работает над чипами для ноутбуков, способными выполнять локальные LLM с 30 млрд. параметров. Intel собрала партнерскую экосистему, которая занимается разработкой ПК с ИИ. Эти устройства с поддержкой ИИ могут быть дороже обычных моделей. Но наценка может оказаться не такой высокой, как ожидалось, и, скорее всего, она будет резко снижаться по мере роста продаж.
«Дорогостоящая часть ИИ на периферии — это в основном обучение, — отмечает Азофф. — Обученная модель, используемая в режиме вывода, не требует дорогостоящего оборудования для работы».
По его мнению, первые периферийные развертывания, скорее всего, будут осуществляться в сценариях, где ошибки и галлюцинации ИИ не имеют большого значения и где вряд ли существует большой риск нанесения репутационного ущерба. В качестве примера можно привести улучшенные рекомендательные системы, поиск в Интернете с помощью ИИ, создание иллюстраций или дизайна. Здесь надежды по выявлению подозрительных ответов или плохо представленных изображений и конструкций возлагаются на пользователей.
Последствия использования LLM на периферии для дата-центров
В то время как индустрия дата-центров готовится к значительному увеличению плотности и мощности для поддержки роста ИИ, что может означать тенденция «LLMs on the edge» для объектов цифровой инфраструктуры?
В обозримом будущем модели, работающие на периферии, будут по-прежнему обучаться в дата-центрах. Таким образом, интенсивный трафик, который сейчас испытывают дата-центры со стороны ИИ, вряд ли уменьшится в ближайшей перспективе. Но модели, обучаемые в дата-центрах, уже меняются. Да, масштабные модели от ведущих поставщиков будут продолжаться развиваться. Но на первый план выходят более мелкие, более целенаправленные LLM.
«К 2027 г. более 50% моделей GenAI, используемых предприятиями, будут относиться к конкретной отрасли или бизнес-функции — по сравнению с примерно 1% в
Работа над уменьшением размера и интенсивности вычислений GenAI приведет к еще более эффективным периферийным LLM, которые смогут работать на различных устройствах. Когда периферийные LLM наберут обороты, они обещают сократить объем обработки ИИ, который необходимо выполнять в централизованном дата-центре. Все дело в масштабе.
Пока обучение LLM в значительной степени доминирует в области GenAI, поскольку модели еще только создаются и совершенствуются. Но представьте, что сотни миллионов пользователей уже используют LLM локально на смартфонах и ПК, а запросы приходится обрабатывать через крупные дата-центры. Столь масштабный объем трафика может перегрузить дата-центры. Однако ценность LLM на периферии может быть осознана только после того, как они войдут в обиход.
LLM на периферии: безопасность и конфиденциальность
Любой сотрудник, взаимодействующий с LLM в облаке, потенциально подвергает организацию риску нарушения конфиденциальности и кибербезопасности.
Поскольку все больше запросов и подсказок выполняется за пределами предприятия, возникают вопросы о том, кто имеет доступ к этим данным. Ведь пользователи задают системам ИИ всевозможные вопросы о своем здоровье, финансах и бизнесе. При этом они часто вводят персональную информацию, конфиденциальные медицинские данные, информацию о клиентах и даже корпоративные секреты.
Переход к небольшим LLM, которые могут выполняться в дата-центре предприятия и, таким образом, не контактировать с облаком, или работать на локальных устройствах, — это способ обойти многие из текущих проблем безопасности и конфиденциальности, возникающих при широком использовании таких LLM, как ChatGPT.
«Безопасность и конфиденциальность на периферии очень важны, если вы используете ИИ в качестве персонального помощника и собираетесь иметь дело с конфиденциальной информацией, которая не должна стать достоянием общественности», — говорит Азофф.
Временные рамки для реализации периферийных LLM
LLM на периферии не станут очевидными сразу — за исключением нескольких специализированных сценариев использования. Но тенденцию к расширению их применения, похоже, уже не остановить.
Исследование Forrester «Infrastructure Hardware Survey» показало, что 67% организаций, принимающих решения по инфраструктурному оборудованию, уже внедрили интеллектуальные системы на периферии или находятся в процессе внедрения. Примерно каждая третья компания также будет собирать данные и проводить ИИ-анализ периферийных сред, чтобы дать сотрудникам возможность получать более ценные и быстрые инсайты.
«Предприятия хотят собирать релевантные данные с мобильных, IoT- и других устройств, чтобы предоставлять клиентам актуальные инсайты, основанные на конкретных сценариях использования, когда они их запрашивают или нуждаются в получении большей ценности, — говорит Мишель Гетц, аналитик по бизнес-инсайтам Forrester Research. — В течение двух-трех лет мы должны увидеть большое количество периферийных LLM, работающих на смартфонах и ноутбуках».
Урезание моделей для достижения более управляемого числа параметров — один из очевидных способов сделать их более применимыми на периферии. Кроме того, разработчики переносят модели GenAI с GPU на CPU, сокращая объем вычислений и создавая стандарты для компиляции.
По словам Гетц, наряду с вышеупомянутыми приложениями для смартфонов, ведущими будут те сценарии использования, которые можно реализовать, несмотря на ограниченные возможности подключения и пропускную способность. Так, инженерные и эксплуатационные работы на местах в таких отраслях, как коммунальное хозяйство, добыча полезных ископаемых и обслуживание транспорта, уже ориентированы на персональные устройства и готовы к использованию LLM. Поскольку такие периферийные приложения LLM имеют коммерческую ценность для бизнеса, ожидается, что переплачивать за полевое устройство или телефон с поддержкой LLM будет не так сложно.
Однако широкое использование LLM на периферии для потребителей и бизнеса должно подождать, пока цены на аппаратное обеспечение не снизятся по мере роста внедрения. Например, Apple Vision Pro в основном используется в бизнес-решениях, где высокая цена на него может быть оправдана.
В ближайших планах также такие сценарии использования, как управление телекоммуникациями и сетями, интеллектуальные здания и автоматизация фабрик. По словам Гетц, реализации более продвинутых сценариев использования LLM на периферии — таких как иммерсивная розничная торговля и автономные транспортные средства — придется подождать еще пять или более лет.
«Прежде чем мы увидим процветание LLM на персональных устройствах, будет наблюдаться рост специализированных LLM для конкретных отраслей и бизнес-процессов, — говорит аналитик. — Как только они будут разработаны, их будет легче масштабировать для внедрения, потому что вам не придется одновременно обучать и настраивать модель, уменьшать ее и развертывать».