










Медея Цнобиладзе
Вызов времени
Компьютерные системы в современном бизнесе обычно являются гетерогенными (неоднородными). Это естественно, так как компании, расширяясь, закупают новые машины, операционные системы, сетевое и прикладное ПО разных типов и от разных производителей. При этом большинство компаний не имеют необходимого инструментария для администрирования таких неоднородных систем. При такой ситуации вероятность сбоя в системе со временем возрастает, а обнаружить ошибку становится все труднее.

В то же время в компаниях повышаются требования к работе компьютерных систем. Некоторым фирмам важна способность системы работать 365 дней в году по 24 часа в сутки, другим необходима гарантированная мгновенная доступность данных на протяжении какого-то периода, для третьих недопустима даже малейшая ошибка в данных, и, наконец, есть компании, для успешного функционирования которых необходимо, чтобы их компьютерная система обладала всеми этими качествами одновременно.
Цена отказа
Цена сбоя компьютерной системы складывается из нескольких компонентов:
- потери прибыли;
- непродуктивной работы персонала;
- растущего недоверия клиентов;
- упущенных деловых возможностей.
По оценкам различных исследователей, простой компьютерных систем обходится американскому бизнесу в миллиарды долларов (порядка сотни тысяч долларов за час простоя). Вот почему технологии, повышающие надежность работы компьютерных систем, так интересны компаниям, чья прибыль и репутация напрямую зависят от корректности и доступности их компьютерной информации.
Отказоустойчивость компьютерной системы -что это такое?
Разработка методов повышения надежности компьютерных систем началась довольно давно. Здесь следует выделить два принципиальных направления: аппаратурные и программные методы. В первом случае компьютер содержит определенные аппаратурные излишки, используемые двояко:
- все операции производятся параллельно на всех одинаковых компонентах, а результат затем логически сравнивается, что помогает выявить ошибки;
- в случае выхода из строя какой-либо детали ее “партнер” продолжает работу без прерываний, а в течение оговоренного срока доставляется и устанавливается заменяющая деталь.
Программный способ предусматривает:
- одновременную работу нескольких машин;
- дублирование данных и процессов;
- процедуры автоматического восстановления операционных систем, данных и приложений.
В прошлом разработка даже очень сложного программного обеспечения обходилась недорого по сравнению с обеспечением надежности оборудования. Однако с развитием вычислительной техники и новых технологий производства ситуация сильно изменилась. На данный момент стоимость обоих методов сравнима между собой, тенденции же таковы, что аппаратурный способ становится все дешевле программного. О преимуществах каждого мы поговорим ниже.
Будем рассматривать все решения по созданию надежных систем с точки зрения следующих, равно важных для бизнеса, критериев: открытость, масштабируемость, надежность, управляемость и стоимость.
Открытой можно называть систему, использующую промышленные стандарты, обеспечивающую необходимую гибкость и легкость интеграции в разнородной среде. Такая система должна быть приспособлена к использованию распространенного инструментария для разработки приложений. Расширение системы и подключение нового набора оборудования и программ должны осуществляться быстро и просто. Открытость систем оставляет компаниям широкий выбор программного и аппаратного обеспечения, а также уменьшает время и стоимость разработки необходимых приложений.
Масштабируемой называется система, характеризующаяся ростом производительности при добавлении ресурсов. Истинно масштабируемая система позволяет точно спрогнозировать рост производительности при добавлении каждой системной единицы. Это облегчает планирование и минимизирует затраты на увеличение вычислительной мощности.
Надежность системы будем рассматривать с точки зрения двух чрезвычайно важных критериев: доступности системы и целостности данных. Для пользователя понятие надежности выражается в готовности системы к использованию, т. е. в отношении времени работоспособного состояния к времени простоя. Для типичного современного сервера эта величина составляет 99%, что означает примерно 3,5 дня простоя в год. На западе принята следующая классификация:
Управляемость системы - наиболее комплексное понятие. В него будем включать следующий набор функций.
- Замена или ремонт поврежденных модулей “незаметно” для работы системы в целом.
- Непрерывное функционирование системы в случае любого изменения конфигурации (сбоя какого-либо модуля или расширения системы).
- Эффективное управление массивами данных даже в случае очень больших объемов, как можно более быстрая обработка очередей, а также эффективное распределение нагрузки между ресурсами.
- Сохранение и архивация данных в режиме on-line.
- Как можно более раннее обнаружение и локализация ошибок и сбоев.
- Мониторинг работы системы.
Для правильной оценки стоимости системы следует учитывать не только цены, но и предполагаемые дополнительные затраты как в момент покупки, так и в ближайшем будущем. Важны также затраты на содержание, расширение и модификацию системы.
Способы повышения надежности
Простые способы. На сегодняшний день разработано множество простых и недорогих способов повышения надежности компьютерных систем. Например, RAID (Redundant Array of Inexpensive Disks - избыточный массив недорогих дисков) существенно уменьшает риск простоя системы из-за отказов накопителей на магнитных дисках, которые являются одной из наименее надежных составляющих современных компьютеров. Отказы других элементов также можно корректировать различными способами, например, отказ блока питания - путем установки избыточных резервных блоков, а сбои в питающей сети - установкой батарей, источников бесперебойного питания (ИБП) или дизель-генераторов.
Кластеризация. Наконец, перейдем к комплексным решениям проблемы повышения надежности. Одним из популярных способов является кластеризация. С точки зрения оборудования кластер - это несколько компьютеров, соединенных коммуникационным каналом и разделяющих общие ресурсы (например, дисковые накопители). Кластер имеет общую файловую систему, а для пользователя он выглядит и управляется как единая система. Современные кластеры способны обеспечить надежность до 99,9% (High аvailability). Все это достигается с помощью специального программного обеспечения, регулирующего скоординированное использование общекластерных ресурсов, осуществляющего взаимный контроль работоспособности и обмен специфической “кластерной” информацией между узлами кластера и т. д. При этом различные простые аппаратные способы повышения надежности (RAID, ИБП) также используются. Отдельные компьютеры называются узлами кластера. Отличительной особенностью кластера является то, что каждый его узел выполняет полезную работу в режиме нормального функционирования и может переключить на себя нагрузку отказавшего узла. Кластерные решения разрабатываются многими известными фирмами, такими, как HP, Digital, IBM и др. Эти решения, конечно, отличаются друг от друга. Более того, различаются даже решения одной фирмы в зависимости от требований пользователей. Однако охарактеризовать общие черты кластеров и рассмотреть их с точки зрения перечисленных критериев вполне возможно. Все известные кластерные решения в той или иной степени обеспечивают высокую готовность приложений и возможность наращивания производительности за счет закупки нового оборудования или замены старого на более мощное.
Кроме того, они включают в себя набор специального программного обеспечения для оптимального распределения ресурсов и удобного администрирования. Некоторые решения имеют следующие составляющие:
2 возможности выявления и корректировки всех видов серьезных системных сбоев;
- программу, обеспечивающую непротиворечивость доступа приложений с разных машин к общим ресурсам;
- утилиты конфигурирования и мониторинга состояния кластера;
- утилиты гибкого конфигурирования файловых систем;
- программные модули управления дисковыми томами и некоторые другие программы.
Как правило, кластерные решения поставляются в комплекте с инструментарием разработчика, позволяющим конструировать необходимое ПО. Рассмотрим общие свойства кластеров.
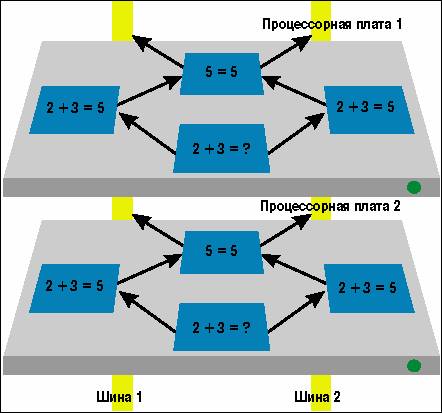
Каждый из задублированных элементов способен продолжать работу в случае отказа одного из элементов-партнеров
Открытость. Как правило, создатели кластеров заявляют об их полной открытости. Однако ограничения все же есть. Прежде всего стоит отметить, что каждое кластерное решение создается под конкретную платформу и непереносимо на другие. Кроме того, при введении кластера в строй создаются специальные сценарии, которые приходится менять при расширении, изменении архитектуры кластера, а также смене системного или прикладного ПО.
Масштабируемость. Производительность кластеров действительно растет с добавлением новых ресурсов. Ее рост можно просчитать с достаточной точностью. Однако это верно лишь для простых кластерных решений. При усложнении архитектуры, а также при введении дополнительных мер по повышению надежности, таких, например, как резервирование процессов, вычислить зависимость производительности от количества оборудования становится чрезвычайно трудно. Следует иметь в виду и то, что сбой в одном из узлов кластера повлечет за собой некоторое, также в простых решениях просчитываемое, снижение производительности системы. Этот факт учитывается заранее при планировании и выборе необходимой архитектуры кластера. Каждое из решений имеет свой предел расширяемости.
Надежность. В случае сбоя в системе типичный кластер действует приблизительно по следующей схеме:
- определение отказа;
- формирование нового кластера;
- запуск сценариев;
- тестирование файловой системы;
- запуск базы данных;
- восстановление базы данных;
- перезапуск приложений.
При использовании хорошо спланированных кластерных решений данные хорошо защищены в случае серьезного сбоя программного или аппаратного обеспечения. Однако при случайных ошибках в работе, например, процессора программный метод защиты данных не дает необходимых гарантий. Что же касается доступности системы, то здесь ситуация следующая.
- В случае серьезного отказа какого-либо узла некоторые приложения могут быть недоступны в течение времени, необходимого для переключения на другой узел.
- Для восстановления нормального режима работы при отказе центрального процессора, памяти, шины или контроллера требуется время. По некоторым оценкам это время составляет 70 секунд и более. Максимально необходимое время зависит от серьезности неполадки, а также от используемых приложений, СУБД и объема данных клиента. Не исключено, что пользователю при этом придется повторно войти в систему.
Кластеры относятся к разряду High аvailability.
Управляемость. В случае замены существенных элементов, операции, которые необходимо будет провести, могут создать определенную задержку в работе системы или даже потребовать прерывания работы пользователя на небольшой срок. Может понадобиться повторить процедуру для другого узла кластера, что опять отразится на пользователе. Подобный же эффект будет наблюдаться при изменении конфигурации кластера. Для улучшения работы с массивами данных многие создатели кластеров сотрудничают с фирмами, выпускающими СУБД, уже на этапе разработки своих идей. В результате создается программное обеспечение, оптимально работающее с данной СУБД. И хотя при разработке кластера учитываются все широко распространенные СУБД, наиболее эффективным получается взаимодействие с СУБД фирмы-партнера, непосредственно участвовавшей в создании конкретного кластера. Запись и архивация данных происходят в режиме on-line сразу в нескольких копиях. Обнаружение ошибок осуществляется программным способом. В разных решениях это делается более или менее эффективно, но не исключены случаи, когда определить источник ошибки (аппаратное или программное обеспечение, какой именно элемент и т. д.) весьма трудно. Программы мониторинга состояния системы поставляются в комплекте или легко конструируются с помощью инструментария разработчика.
Стоимость. Рассмотрим, наконец, структуру цен на кластерные решения. Цены сильно различаются в зависимости от выбранной архитектуры, степени интеграции узлов в кластере, функциональной полноты и возможностей наращивания. Кроме того, покупателям кластеров следует учесть дополнительные затраты по следующим статьям расходов:
- возможная закупка дополнительного оборудования;
- оплата консультантов;
- обучающие тренинги для персонала;
- тестирование системы;
- скрупулезное планирование всех возможных событий и изменений в работе кластера;
- подготовка необходимой документации.
Если учесть все эти затраты, то средний добротный кластер обойдется от 400 до 500 тысяч долларов.
Отказоустойчивые компьютеры. Основным соперником кластеров сегодня являются мощные одно- или многопроцессорные серверы с отказоустойчивой аппаратной “начинкой”. В отличие от создателей кластеров разработчики Fault tolerant (FT) систем с самого начала ставили перед собой задачу предотвращения и по возможности исключения, а не сокращения времени простоев. В основу архитектуры FT-серверов положено использование задублированных элементов, число которых в разных серверах может быть разным.
На сегодняшний день производством FT-серверов занимаются две известные компании: Tandem Computers и Stratus Computer. Последняя была образована в 1980 году, первые компьютеры она выпустила в 1982-м. С самого начала компания взяла ориентацию на аппаратный способ повышения надежности. Ее серверы оснащаются отказоустойчивой ОС FTX или (с 1996 года) HP-UX. Компания Tandem существует с 1974 года, первые компьютеры выпустила в 1976-м. Поначалу в серверах этой компании применялся комбинированный аппаратно-программный способ повышения надежности, так что по сути это были (и выпускаются до сих пор) кластеры повышенной надежности. Реализованы они были на разработанной самой компанией ОС Guardian. Система UNIX стала использоваться только в начале 90-х.
Итак, в серверах фирмы Stratus и серверах новой линии Integrity S4000 компании Tandem происходит примерно следующее. Любая команда выполняется одновременно на всех элементах, и результаты операций логически сравниваются, что предотвращает распространение ошибки. Каждый из задублированных элементов способен продолжать работу в случае отказа одного из элементов-партнеров таким образом, что прикладная система не почувствует отказа и ее функционирование не ухудшится. Например, на аппаратном уровне один процессор в таком сервере - это четыре ЦП. Каждая пара ЦП и основная память образуют один SPU (system processing unit), а пара SPU - один процессор. При нормальной работе на каждом SPU обрабатывается одна задача. Если результат работы на одном ЦП отличается от результата на втором, то система диагностирует неисправность аппаратного модуля SPU и автоматически изолирует его. Другой модуль при этом продолжает работу до тех пор, пока его партнер не будет заменен в “горячем” режиме. Такая технология была названа continuous availability (постоянная доступность).
Открытость. Как правило, современные мощные FT-серверы оснащены специально модифицированной отказоустойчивой версией операционной системы UNIX. Это означает, что тысячи различных приложений, созданных под эту ОС, работают на таких серверах без ограничений. Конечно, это значит и то, что дальнейшее развитие системы также придется ориентировать на UNIX. Понятно, что создание новых приложений не осложнено дополнительными проблемами, а благодаря полному соответствию операционной системы международным стандартам открытости и поддержке промышленных коммуникационных протоколов создаются условия для эффективного взаимодействия с разнородными компьютерами в рамках единого комплекса.
Масштабируемость. Системы обладают хорошей расширяемостью, и вычислить прирост производительности возможно. Важно отметить, что благодаря аппаратурной избыточности таких серверов, как, например, Stratus Continuum, при отказе какого-либо ресурса снижения производительной мощности не происходит.
Надежность реализована преимущественно аппаратным способом. Как уже указывалось, максимальное время недоступности системы для пользователей составляет в среднем несколько минут в год. Целостность данных обеспечивается.
Замена каких бы то ни было элементов системы проходит незаметно для пользователей. Расширение системы также не влияет на их работу и может проводиться в динамическом режиме. Переконфигурация в зависимости от версии используемой ОС может потребовать перезагрузки системы. Многие составные элементы таких систем являются самотестирующимися, так что ошибка обнаруживается мгновенно, на машинном такте ее возникновения, и элемент изолируется от остальной системы. Кроме того, существует и программное тестирование данных на предмет ошибок.
Структура цен на подобные системы следующая. Сам сервер может стоить довольно дорого. Но за счет продуманной конструкции и несложности эксплуатации нет дополнительных затрат на консультантов и специализированный персонал. Отсутствуют и скрытые затраты на планирование возможных сбоев, написание и модификацию сценариев. Таким образом, при учете всех затрат FT-система обойдется примерно во столько же, что и кластерное решение, а часто и дешевле.
Обзор существующих решений
Чтобы лучше представить положение дел, кратко рассмотрим несколько вариантов решений из обоих лагерей.
Решения корпорации Digital. Digital предлагает гамму кластерных решений, включающую эталонные OpenVMS Cluster, производительные TruCluster на Digital Unix и недорогие и простые в установке Digital Clusters for Windows NT.
Кластеры OpenVMS существуют уже более 10 лет. Их программное обеспечение позволяет узлам кластера совместно использовать не только дисковые подсистемы внешней памяти, но и накопители на магнитных лентах, CD-ROM и другие ресурсы. Такой кластер с точки зрения и пользователя, и системного администратора выглядит как единое целое, представляя собой общее поле ресурсов - процессоров, дисковых массивов, магнитных лент, очередей печати и пакетных заданий. Наличие DLM (Distributed Lock Manager) позволяет приложениям работать с одними и теми же данными на всех узлах. В эти кластеры можно объединять VAX и/или Alpha любых моделей и конфигураций. В кластер OpenVMS можно собрать до 96 узлов.
Семейство TruCluster включает несколько специализированных вариантов. TruCluster Production Server предназначен для приложений, работающих одновременно на всех узлах с использованием механизма DLM. В этом кластере обеспечивается наиболее высокий уровень готовности, поскольку приложения постоянно функционируют на всех узлах и в случае краха одного узла нет задержки, связанной с перезапуском приложений. Благодаря использованию коммуникационной технологии Memory Channel и сотрудничеству с Oracle уже на стадии разработки TruCluster Production Server показывает лучшую среди кластеров производительность при работе с Oracle7 v7.3. Более дешевый TruCluster Available Server не использует Memory Channel и DLM-технологий. В таком кластере на разных узлах выполняются не взаимодействующие между собой приложения, а сами узлы являются всего лишь “горячим резервом” друг для друга. Под Windows NT Digital создала простенький кластер без механизма DLM.
Решения IBM. IBM разработала кластерное решение, предназначенное для компьютеров IBM RISC System/6000, PowerStation и PowerServer. Кластеры HACMP (High Availability Cluster MultiProcessing) позволяют объединять до четырех машин. Предлагается четыре варианта конфигурации:
- один процессор находится в постоянной готовности и “подстраховывает” один, два или три других работающих процессора;
- работают четыре процессора, один (дополнительный) является “горячим резервом” попеременно для каждого из них по заранее определенному графику или по ситуации;
- работают четыре процессора. В случае отказа одного из них нагрузка перераспределяется между оставшимися;
- четыре процессора работают одновременно с одними и теми же общими данными.
В основе строения HACMP-кластера лежит менеджер кластера, ответственный за проверку статуса кластерных компонентов, мониторинг системы и режимы работы процессоров. В случае сбоя менеджер кластера отвечает за весь процесс восстановления нормальной работы системы, обеспечение максимальной доступности и прозрачности для пользователя. Поставляются решения IBM в комплекте с богатым набором программных приложений, таких, как, например, DLM. Поддержка стандартного UNIX-интерфейса обеспечивает относительную легкость инсталляции, конфигурирования и работы кластера в сети, возможность контроля и администрирования кластера с одной консоли и переносимость в UNIX-системы и подсистемы. В своем кластерном решении IBM предусмотрела поддержку всех дисковых подсистем, а также ряда процессоров собственного изготовления. В HACMP-кластере работают без изменений около десяти СУБД, среди которых такие известные, как Oracle, Informix, Sybase и, конечно, DB/6000. Этот кластер особенно удобен для владельцев оборудования IBM, так как позволяет им повысить надежность компьютерной системы, пользуясь услугами той же самой компании.
Решения компании Tandem. Интересно рассмотреть два типа решений, предлагаемых компанией Tandem - серию Himalaya, включающую в себя К200, 2000 и К20000 с различными возможностями и производительностью, и новую серию Integrity S4000. Himalaya является последней реализацией прежнего подхода Tandem к созданию отказоустойчивых серверов, т. е. по сути представляет собой кластер, обеспечивающий надежную работу преимущественно программным способом. От кластеров эти серверы выгодно отличает то, что благодаря некоторым аппаратным методам защиты данные надежно сохраняются даже при случайной ошибке в системе. Во всем остальном это типичный кластер со всеми задержками, неизбежными при восстановлении нормальной работы после сбоя или изменении конфигурации системы. В серверах этой серии используется ОС NonStop Kernel, по сути являющейся модификацией ОС Guardian. Взаимодействие с другими системами осуществляется с помощью шлюзов. Специально под свои серверы компания также поставляет мощную и рационально сконструированную, хотя и не стандартную РСУБД. Вообще стоит отметить, что Guardian является действительно отказоустойчивой операционной системой, но при этом она не поддерживает ни стандартных СУБД, ни стандартных ОС и сетевого обеспечения, ни стандартного монитора транзакций, ни стандарта взаимодействия распределенных систем. Все серверы этой линии (кроме К112) базируются на процессорах MIPS. Самый мощный сервер этой группы К20000 использует системный кабинет с процессором R4400 с частотой 200 МГц. Поддерживается два или четыре канала ввода-вывода на каждый ЦП, а также два асинхронных и один синхронный порт (отдельно от портов на дополнительной плате ввода-вывода). Система сборки в Tandem базируется на стандартном системном кабинете, включающем два ЦП, несколько дисков и коммуникационных устройств. Для получения более мощной системы собирают несколько таких системных кабинетов, а ОС Guardian обеспечивает общение с группой как единым целым.
Не менее интересны серверы семейства Integrity S4000 с реализованной технологией подсистемы ввода-вывода ServerNet. Они базируются на RISC-процессорах MIPS R4400 с тактовой частотой 200 МГц и работают в операционной системе NonStop-UX 3.0, совместимой с UNIX SVR4.2 и поддерживающей широкий спектр промышленных протоколов. В этой серии Tandem реализует аппаратный метод повышения надежности. Два ЦП и основная память составляют один элемент SPU (System Processing Unit). Память не задублирована, так что при выходе из строя одного из ЦП или памяти заменяется весь SPU. Серверы Integrity S4000 поддерживают до четырех процессоров и 1 Гб оперативной памяти. Tandem стандартно предоставляет годовую гарантию на аппаратное и программное обеспечение, а также техническую поддержку в течение года, включающую консультации по системе c выездом к заказчику. Время, в течение которого компания обязуется ответить на любой вопрос, составляет от двух до шестнадцати часов.
Решения компании Stratus. Stratus создала новую серию серверов - Continuum, поддерживающую технологию CA (Continuous Availability) этой же компании. Серверы Continuum выпускаются в трех модификациях: 400, 600, 1200 и базируются на процессорах HP PA-RISC 7100/8000. По желанию заказчика используется либо открытая операционная система FTX 3.2, представляющая собой отказоустойчивую реализацию UNIX SVR4 разработки фирмы Stratus, либо операционная система HP-UX, отказоустойчивая реализация наиболее распространенной UNIX-системы. Поддерживается до двух логических процессоров, до трех пар связных процессоров ввода-вывода, до 3 Гб дуплексной памяти, до 864 Гб задублированной внутренней дисковой памяти и до 12 контроллеров ввода-вывода. Шина ввода-вывода PCI позволяет осуществлять быструю интеграцию на эту платформу высокоскоростных коммуникаций. Вообще разработчики компании Stratus наиболее последовательны в реализации именно аппаратных способов повышения надежности. В результате задублированные самоконтролирующиеся аппаратные средства и логические блоки сводят к минимуму вероятность выхода из строя прикладной или операционной системы. Кроме того, при таком подходе нет необходимости в плановых профилактических простоях, столь неприятных для критически важного использования компьютерных систем. Можно сказать, что серверы компании Stratus обладают отличными показателями управляемости. Замена любого элемента, переконфигурация сервера происходят в режиме on-line, ошибки определяются и локализуются мгновенно. Помимо этого пользователям предоставляется широкий выбор баз данных реального времени, в том числе Oracle, Sybase и Informix. Серверы этого семейства обеспечивают лучшее среди FT-систем соотношение производительность/стоимость. Очень существенным представляется факт наличия сети дистанционного обслуживания заказчиков. Все системы Stratus соединены через модемы или по сети Х.25 с центром поддержки заказчиков. Сеть и поддерживающее ее программное обеспечение называются RSN (Remote Service Network - сеть удаленного обслуживания). Она автоматически информирует Stratus об отказах аппаратных средств и питания, и заменяющая деталь доставляется по назначению в течение суток, даже если самому клиенту еще ничего не известно об отказе в системе. Так же автоматически отмечаются устранение неполадок, установка новой операционной системы. При помощи этой сети инженеры Stratus (разумеется, с разрешения пользователя) могут войти в систему для ее анализа. Таким образом существенно сокращается время устранения любой неполадки, поиска и замены любых необходимых деталей, что в конечном итоге еще больше повышает надежность системы.
Выбор между “постоянной” и “высокой” доступностью
Если вашей компании необходимо повысить надежность компьютерной системы и вы выбираете между HA и CA, необходимо тщательно продумать ответы на следующие вопросы.
- Насколько важны комьютерные данные для компании на текущий момент и каким станет их значение в ближайшем будущем?
- Насколько доступность данных влияет на возможность для компании получить прибыль или вовремя выполнить свои обязательства (перед клиентами, партнерами и т. д.)?
- Как долго компьютерные данные могут оставаться недоступными для компании и ее клиентов без каких-либо последствий для репутации компании?
- Можно ли оценить, во сколько компании обходится каждая минута простоя и какова общая сумма?
- Каким машинным парком и каким оборудованием обладает компания на данный момент?
- Какие денежные средства компания готова выделить на приобретение и поддежку системы?
Попробуем рассмотреть возможные варианты. Предположим, для компании важна в первую очередь целостность данных, а их постоянная доступность необязательна. То есть недоступность данных в течение нескольких минут или возможная замедленная их обработка никак не влияют на прибыль компании и не вызывают недовольства клиента. Предположим, компания уже владеет парой неплохих машин, которые можно объединить в кластер, и не нуждается в дальнейшем существенном наращивании вычислительной мощности. Если при этом ей удобно вначале выплатить не очень крупную сумму, а затем платить понемногу за некоторые дополнительные услуги, то вполне подходящим решением является кластер. Он обеспечит достаточную надежность, потери от простоя не повлияют на благосостояние компании, а стоимость системы будет выплачена как бы в рассрочку (сюда входит оплата самого решения, вспомогательного ПО, услуг консультантов, обучения персонала, стоимость планирования, изменения сценариев и т. д., причем все это может оказаться дороже FT-решения). Остается только связаться с представителями компаний, предоставляющих кластерные решения, обдумать их предложения и выбрать. Лучше всего остановить выбор на той компании, которая предоставит как можно больше сервисных услуг при как можно более низкой цене - это может существенно сократить расходы на содержание кластера.
Если же данные важны чрезвычайно, если каждая минута задержки уменьшает прибыль и повышает недоверие клиентов, стоит очень серьезно обдумать свой выбор. Даже компании, уже обладающей серверами, недостаточно просто соединить их в кластер. Они могут не подойти для работы с критически важными приложениями. Дело в том, что при конструировании “обычных” серверов в списке критериев на первом месте стоит цена, а не целостность данных. Нужны специально сконструированные процессоры, диски, контроллеры и другие поддерживающие подсистемы для действительной надежности. Ведь хотя случайные ошибки в современных процессорах и не очень частое явление, отсутствие системы самотестирования может привести к тому, что ошибка пройдет незамеченной, а в результате данные будут безвозвратно потеряны или, что еще хуже, неузнаваемо искажены. Если вашей компании требуется разветвленная сложная сеть, стоит подумать, готовы ли вы выделить ресурсы на скрупулезное планирование, прогнозирование и документирование возможных ситуаций в системе. Следует также оценить реальные вложения в кластер и сравнить их со стоимостью СА-систем. При этом рекомендуется подсчитать ежегодную стоимость для компании часов простоя, неминуемых при использовании кластерного решения. В подавляющем большинстве случаев для подобных компаний выгоднее использовать FT-серверы, тем более что с внедрением таких операционных систем, как, например, HP-UX, двоично совместимой с самой популярной UNIX и используемой Stratus, работа с серверами не требует даже переучивания персонала. Если вы склоняетесь к использованию CA-технологии, то остается взвесить, насколько вашей компании нужен такой сервис, как, например, RSN-сеть, возможность выбора ОС, управляемость системы или ее расширяемость. Таким образом вы обеспечите своей компании настоящую надежную систему.
C автором можно связаться по телефону: (095) 733-9520.






