











РЕЦЕНЗИИ
Андрей Алексеев, Наталья Карасева
Факт сам по себе мало значит - важна его интерпретация.
Д. И. Менделеев
Когда в какой-нибудь области собираются, скапливаются некие данные, рано или поздно возникает необходимость что-то с ними сделать: переработать, проинтерпретировать, получить объяснения произошедшему, а также спрогнозировать последствия. Можно задуматься и о том, какие именно данные стоит собирать, чтобы получить ответы на задаваемые вопросы о предметах, событиях, процессах. Наконец, иногда целесообразно попытаться определить, есть ли смысл вообще искать требуемые ответы на основе имеющейся информации или это бесполезно. Ярчайший пример интерпретации собранных данных, на основе которой стали возможными выводы, обладающие предсказательной силой, дает нам история создания Д. И. Менделеевым одноименной периодической системы.
Новый виток в развитии электронных средств хранения и обработки данных привел к ситуации, когда объектом повышенного интереса стал сам инструментарий для поиска в архивах и базах данных “осколков” полезных в конкретной ситуации знаний. Возникло понятие, которое по-русски стали называть “добыча”, “извлечение” или “раскопка” данных. За рубежом утвердился термин “Data Mining”. Нередко наряду с Data Mining встречаются термины “обнаружение знаний в базах данных” (knowledge discovery in databases) и “интеллектуальный анализ данных”. Их можно считать синонимами.
И вот появилась книга, авторы которой замахнулись на многое, попытавшись не только изложить разные подходы к обнаружению и извлечению знаний, но и сопроводить их конкретными примерами.
Дюк В., Самойленко А.. Data Mining. Учебный курс +CD. СПб.: Питер, 2001. - 386 с., ил.

Начинают авторы с общеизвестного: по мере совершенствования технологий записи и хранения данных на нас обрушиваются колоссальные потоки информационной руды в самых различных областях. Деятельность любого предприятия (коммерческого, производственного, медицинского, научного и т. д.) теперь сопровождается регистрацией и записью разнообразных подробностей его функционирования. Что делать с этой информацией? Стало ясно, что без продуктивной переработки потоки сырых данных образуют никому не нужную “свалку”. Поэтому естественно сформулировать современные требования к системам интеллектуальной переработки данных следующим образом:
- данные имеют неограниченный объем;
- данные являются разнородными (количественными, качественными, текстовыми);
- результаты должны быть конкретны и понятны;
- инструменты для обработки сырых данных должны быть просты в использовании.
Необходима автоматизация выявления скрытых правил и закономерностей в наборах данных. Именно так авторы определяют назначение новых инструментальных средств. Ведь за редчайшими исключениями человеческий разум сам по себе не приспособлен для восприятия больших массивов разнородной информации. Мы не можем уловить более двух-трех взаимосвязей даже в небольших выборках. Не оттого ли именно такую размерность имеют логические и комбинаторные задачки, столь часто предлагаемые в научно-популярных изданиях для проверки сообразительности и умения логически мыслить: “Из трех пассажиров купе один является врачом, второй едет на правой верхней полке, фамилия третьего - Сидоров и он никогда не говорит правды+”
Далее авторы указывают, что традиционная математическая статистика, долгое время претендовавшая на роль основного инструмента анализа данных, также нередко дает сбои при решении задач из реальной жизни. Она оперирует усредненными характеристиками выборки, которые часто являются фиктивными величинами (типа средней температуры пациентов по больнице, средней высоты домов на улице, состоящей из небоскребов и лачуг, и т. п.). Поэтому методы математической статистики оказываются полезными главным образом для проверки заранее сформулированных гипотез (verification-driven data mining) и для “грубого” разведочного анализа, составляющего основу оперативной аналитической обработки данных (on-line analytical processing, OLAP).
Переходя к сравнительному обсуждению, авторы характеризуют современные технологии Data Mining (discovery-driven data mining) как основанные на переработке информации с целью поиска шаблонов (паттернов), характерных для каких-либо фрагментов неоднородных многомерных данных. В отличие от оперативной аналитической обработки данных, в инструментарии Data Mining задача формулировки гипотез и выявления необычных (unexpected) шаблонов переложена с человека на компьютер. Очень хорошо поясняет это различие пример, взятый из публикации “Knowledge Discovery Through Data Mining: What Is Knowledge Discovery?” - Tandem Computers Inc., 1996. (Русский перевод этой полезной работы под названием “Обнаружение знаний - что это такое?” можно найти по адресу: www.bizcom.ru/rus/bt/1997/nr4/31.htm.)
В главах 2-5 авторы проводят обстоятельный аналитический обзор методов и программных продуктов Data Mining. Подробно, с приведением практических примеров рассматриваются наиболее популярные инструментальные средства поиска нетривиальных и реально полезных, доступных интерпретации знаний: статистические пакеты, нейросети, эволюционные алгоритмы, в том числе так называемые генетические, средства обнаружения логических закономерностей в данных. Мы здесь вынуждены ограничиться перечислением тем и констатацией того факта, что материал изложен увлекательно и последовательно. Теория подкрепляется примерами в тексте и на компакт-диске, сопровождается обсуждением программных продуктов лидеров рынка. В приложениях даны описания подходов к изучению предметных наборов данных, а также кратко изложены понятия и методы, связанные с классификацией знаний, современными способами их представления, экспертными системами, методами работы инженеров по знаниям. Завершает книгу толковый словарь основных терминов интеллектуального анализа данных. Все главы снабжены информативными библиографическими ссылками, позволяющими более основательно изучить затрагиваемые темы.
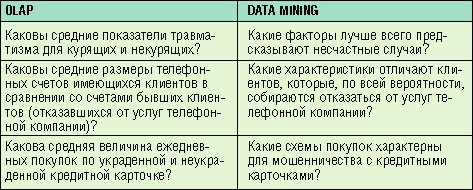
Примеры формулировок задач при использовании методов OLAP и Data Mining
Лидеры рынка Data Mining связывают развитие этих систем с использованием их в качестве интеллектуальных приложений, встроенных в корпоративные хранилища данных (Data Warehousing). В этом развитии принимают участие практически все крупнейшие корпорации ПО (см., например, http://www.kdnuggets.com). Так, Microsoft непосредственно руководит большим сектором данного рынка (издает специальный журнал, проводит конференции, разрабатывает собственные продукты: www.olap.ru/desc/microsoft/ms_dm.asp).
Представляемая вам книга дает повод подумать о том, что суммарно накопленные в обсуждаемой области сведения и методики требуют повышенного внимания не только специалистов, но и представителей многих профессий, связанных с прикладными задачами по обработке информации
Как подчеркивают авторы, сфера применения Data Mining ничем не ограничена - она везде, где имеются какие-либо данные. То же самое, по нашему мнению, можно предположить относительно круга возможных читателей. В качестве первоначального введения в предмет ее можно рекомендовать как студентам и аспирантам, так и широкой аудитории читателей, интересующихся проблемами анализа данных.
Возвращаясь к теме появления на свет периодической системы Менделеева, хочется задуматься: а какой оказалась бы ее судьба, обладай уважаемый Дмитрий Иванович электронными помощниками для поиска, анализа и обобщения из числа вышеназванных? Появилась ли бы система быстрее? Или, как знать, не посчитал ли бы великий ученый сам по себе процесс освоения софта достаточно интересным занятием, да и отложил бы свою химию на потом?






