










Заметки из лаборатории
Уникальная способность автономного браузера Web редактировать HTML-страницы перевешивает его недостатки
Web Retriever 2.0 корпорации Folio (Прово, шт. Юта) не обладает всеми возможностями конкурирующих автономных браузеров Web, особенно в части планирования времени копирования страниц, однако предоставляемая этой программой возможность манипулирования HTML-страницами уникальна.
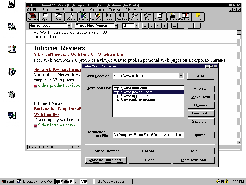
Web Retriev 2.0 корпорации Folio позволяет легко создавать списки URL для копирования по расписанию.
Для каждого URL можно задать свое время копирования
Чтобы увидеть картинку в натуральном размере дважды щелкните мышкой по этой строке.
В отличие от продуктов WebX фирмы Traveling Software и OM-Express фирмы OpenMarket, которые просто сохраняют HTML-страницы на жестком диске для последующего просмотра, Web Retriever сначала сжимает их, а затем преобразует в частный формат Infobase корпорации Folio. Infobase - это технология баз данных для гипертекстовых “плоских” файлов. Выпуск программы, цена которой составляет $39,95, начался в августе.
Связи страниц Web преобразуются в гипертекстовые связи Infobase и отображаются в виде зеленого подчеркнутого текста. Двойной щелчок на связи переносит пользователя из одного места в другое. Связи с онлайновыми страницами Web отображаются в виде красного подчеркнутого текста. Web Retriever успешно запустил выбранный браузер Web и отобразил заданный URL (универсальный указатель ресурса).
После преобразования отредактированную версию документа можно включить в другие программы или распространить по электронной почте. В состав пакета входит программа для просмотра файлов формата Infobase, так что они доступны почти на любой системе. Web Retriever - это первый автономный браузер, обладающий такой возможностью редактирования.
В тестах PC Week Labs весь процесс прошел почти без запинок. Однако при преобразовании HTML-страницы в файл Infobase не полностью сохраняется ее целостность, и потому при просмотре страницы в формате Infobase истинный режим WYSIWYG не выдерживается.
Однако, по нашему мнению, этот недостаток - лишь мелкая неприятность, поскольку содержимое страницы изменяется уже в самом процессе редактирования. Пользователи могут добавлять свои пометки или выделять отдельные области страницы.
Отсутствие гибкого планирования
Основной недостаток Web Retriever - это отсутствие гибкости при планировании копирования страниц.
Мы могли запланировать только автоматическое копирование страниц один раз в 24 часа. При работе с Web Retriever нельзя запланировать повторяющиеся копирования; кроме того, нельзя планировать более чем на 24 часа вперед.
Далее, Web Retriever не предоставляет возможности идентификации с паролем для тех пользователей, которым нужно вводить пароль при подключении к поставщику услуг Internet. Таким образом, эти пользователи не смогут запланировать копирование страниц.
Другие автономные браузеры, такие, как WebX, позволяют пользователям копировать страницы несколько раз в день и даже отслеживать изменения на узлах Web. При изменении страниц на узле требуемые связи автоматически обновляются.
Однако Web Retriever предоставляет выбор параметров для ускорения копирования. Мы могли ограничить не только число уровней страниц Web, которые хотели бы получить, но также общее число страниц и объем дискового пространства, отведенного для их размещения.
Поскольку файлы Infobase могут быстро разрастаться до чрезвычайно больших размеров, Web Retriever помогает пользователям ориентироваться в сохраненном материале, используя структуру HTML-страниц Web.
Например, названия и заголовки используются для автоматического создания оглавления с гиперсвязями. Чтобы перейти к какому-либо разделу базы данных Infobase, мы могли просто щелкнуть на этом разделе в оглавлении.
Web Retriever индексирует каждое слово файла Infobase, так что поиск фрагментов текста проходит очень быстро, а сами функции поиска показались нам весьма гибкими и всеобъемлющими. Например, мы легко нашли нужные нам данные в 500-страничном файле Infobase, воспользовавшись функцией Web Retriever для поиска по логическому выражению, составленному из нескольких слов.
При всей пользе, которую приносят автономные браузеры Web, они могут быстро заполнить весь жесткий диск скопированными данными. Web Retriever помогает сэкономить место на диске за счет сжатия данных во время их копирования по технологии Underhead корпорации Folio. Мы скопировали серию URL общим объемом 2,5 Мб, и Web Retriever сжал их в файл Infobase объемом 1,5 Мб; таким образом, экономия составляет целых 40%.
Аналогично другим автономным браузерам Web Retriever не может копировать Java-приложения, компоненты ActiveX и подключаемые программы для браузера корпорации Netscape Communications.
В корпорацию Folio можно обратиться по телефону: (801) 229-6700 или по адресу: http://www.folio.com.
Херб Бетони
Со старшим аналитиком Хербом Бетони можно связаться по адресу: herb_bethoney@zd.com.
Чтобы восполнить недостаток возможностей планирования, можно использовать Web Retriever в сочетании с другими автономными браузерами, которые предлагают гибкие функции планирования






