В своем выступлении на конференции «All Day DevOps» Йонит Грубер-Хазани, инженер по работе с клиентами Google Cloud, рассказала о том, как мышление «платформа как продукт» помогает организациям осуществить облачную миграцию. Портал The New Stack приводит некоторые паттерны и антипаттерны платформенного инжиниринга, которые она рассмотрела, и уточняет, где они остаются неизменными, а где отличаются в зависимости от размера компании.
По мере того как крупные организации переходят на облачные технологии, платформенный инжиниринг становится интересным способом облегчить этот переход — и, возможно, заранее предусмотреть и устранить когнитивную нагрузку, которую он часто несет с собой.
Почему именно платформенный инжиниринг?
«Представьте, что к вашей команде присоединился новый разработчик, — начала свое выступление Грубер-Хазани. — Допустим, вы даете ему новый ноутбук и говорите: „Вот новый пустой ноутбук, иди и найди ОС, которую ты хочешь, и установи ее, поставь систему безопасности, настрой сеть, установи антивирус и IDE [внутреннюю среду разработчика] и добавь себя в Active Directory (или другую систему управления пользователями в вашей компании). И тогда ты сможешь начать разработку“».
Конечно, вы так не поступаете. ИТ-отдел предоставляет разработчику ноутбук, на котором все это загружено и готово к работе. «Вы даете ему все необходимое, чтобы он мог сосредоточиться и начать свой путь разработчика в компании», — сказала Грубер-Хазани.
Она рассказала об антипаттерне, который часто становится причиной внедрения платформенного инжиниринга. Мы никогда не заставляем людей самостоятельно настраивать касающиеся из процессы начисления зарплаты и управления персоналом — так почему же мы предлагаем им заниматься несущественной работой? Платформенная команда стремится решить эту проблему с помощью поддержки разработчиков ПО, прокладывая им Yellow Brick Road — путь, в конце которого человека ждёт достижение цели и воплощение мечты. Команды разработчиков по-прежнему могут быть самостоятельными в создании ценности для конечного пользователя, но им не нужно разбираться во всех облачных технологиях, операциях, безопасности и т. д.
По словам Грубер-Хазани, подобную настройка «из коробки» оптимально применить к адаптации новых приложений, новых разработчиков и новых команд разработчиков, «чтобы предоставить им наилучший опыт разработки, когда они начнут создавать приложения в вашей производственной системе».
Именно поэтому крупные организации не должны предоставлять весь облачный ландшафт — и особенно огромный ландшафт нативного облака с открытым исходным кодом — разработчикам или даже командам, чтобы они сами выбирали, что им использовать.
«Вы не должны этого делать, потому что тогда вы получите джунгли, ведь команде DevOps придется управлять всем, что они выберут, а вам нужно будет это поддерживать, обслуживать и мониторить, — заявила Грубер-Хазани. — И вам не нужно, чтобы разработчики столкнулись со всем этим фоновым шумом. Они нужно работать над приложением и бизнес-логикой, лежащей в его основе».
Итак, зачем нужен платформенный инжиниринг? Чтобы снизить когнитивную нагрузку на разработчиков, позволив им достичь состояния потока, в котором они могут просто сосредоточиться на создании своих приложений — и все это с помощью платформы.
Опыт разработчика и постоянно растущая когнитивная нагрузка
Опыт разработчика, или DevEx, по определению Грубер-Хазани, «это то, ради чего мы приходим на работу каждое утро. И продолжаем это делать из года в год. Он определяет, насколько счастливыми мы чувствуем себя в своей трудовой жизни, насколько реализованными мы себя чувствуем и насколько полезными для других мы себя чувствуем в конце дня. Это то, что делает нас людьми и способными плодотворно работать».
DevEx, в свою очередь, оказывает влияние на производительность, продуктивность, удовлетворенность работой, качество, удержание кадров.
Грубер-Хазани рассказала о трех метриках DevEx для измерения продуктивности:
- Состояние потока. Попадание «в зону» — это когда разработчик полностью вовлечен в работу и получает от нее удовольствие. Чтобы войти в этот поток, требуется в среднем 23 минуты, это время может быть легко увеличено такими вещами, как ожидание, пока кто-то другой сделает что-то.
- Петли обратной связи. Речь о реакции и времени реакции на то, что делает разработчик. Грубер-Хазани привела в качестве примеров ожидание перекомпиляции кода или ожидание получения доступа к другой виртуальной машине. Рецензирование кода — важная петля обратной связи, которую необходимо обеспечить. В «State of DevOps Report 2023» (так называемый отчет DORA) показано, что команды с более быстрыми обзорами кода имеют на 50% более высокую производительность доставки ПО.
- Когнитивная нагрузка. «Это умственная деятельность, необходимая для выполнения задачи, — пояснила она. — И она может помешать разработчикам создавать и доставлять ценность». Плохая документация и ручные, нестабильные действия увеличивают негативный опыт разработчиков и их выгорание, в то время как отчет DORA за этот год показал, что качественная документация повышает производительность на 25%.
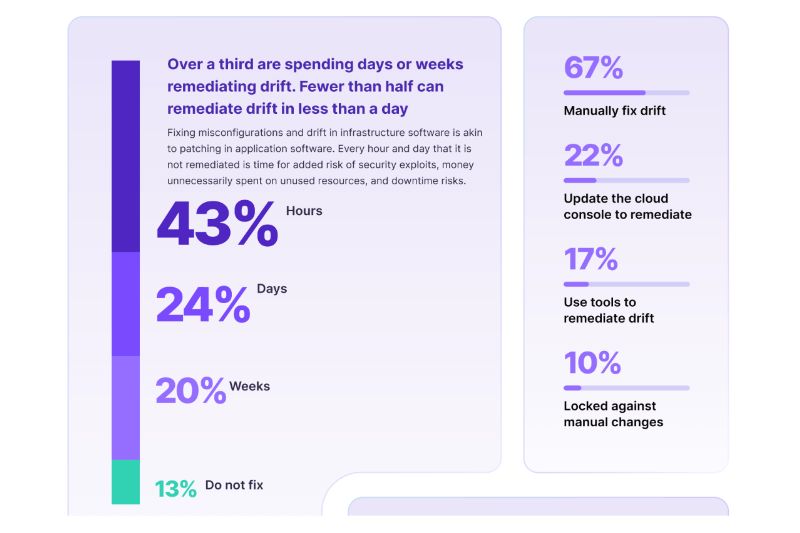
Прошлогодний опрос StackOverflow продемонстрировал, что 62% всех респондентов тратят на поиск ответов или решений проблем более 30 минут в день, а 25% — более часа. Это неизбежное разочарование как нарушает состояние потока, так и увеличивает когнитивную нагрузку, поэтому документирование является неотъемлемой частью любой стратегии развития платформы в компаниях любого размера.
Что такое платформенный инжиниринг?
Если в каждой организации платформа по своей сути отличается, то какие общие закономерности характеризуют социотехническую дисциплину платформенного инжиниринга? Грубер-Хазани выделяет следующие:
- Повторяющиеся инструменты и модели, такие как инфраструктура как код и многократно используемые конвейеры CI/CD.
- Самообслуживание через API.
- «Торговый автомат услуг», особенно в крупных организациях, где платформа должна обслуживать от 50 до 100 команд разработчиков.
- Мощеные дороги с ограждениями.
- Специфические для организации рабочие процессы.
За последние пару лет работы с заказчиками Грубер-Хазани обнаружила, что большинство приложений нуждаются в одних и тех же ограждениях:
- мониторинг;
- протоколирование;
- отладка;
- безопасность, аутентификация и авторизация;
- подключение к бэкенд-системам (например, к структурированным базам данных);
- благодатная деградация и обход отказов;
- снижение и дросселирование нагрузки;
- общие разделяемые библиотеки;
- инфраструктура тестирования;
- инфраструктура выпуска.
Все это, как правило, может быть реализовано в рамках платформы или набора платформ, чтобы помочь командам платформ достичь следующих целей по улучшению обслуживания разработчиков:
- уменьшение технической сложности;
- снижение затрат;
- повышение скорости разработки;
- обеспечение безопасности и защитных ограждений;
- снижение когнитивной нагрузки, трудозатрат и выгорания.
Это достигается путем прокладывания «золотого пути» к производству с использованием лучших практик и защитных ограждений. Зачастую все это облекается в каталог услуг — или, как правило, в серию каталогов услуг для разных групп разработчиков, — который абстрагируется за внутренним порталом для разработчиков, например Backstage или Spinnaker.
По словам Грубер-Хазани, еще один способ отличить платформенную инженерию от прежних платформ, построенных по принципу «сверху вниз», — это мышление «платформа как продукт», которое заставляет каждого инженера платформы по совместительству быть менеджером продукта. Оно требует, чтобы каждая команда платформы балансировала бизнес-цели, внутренние потребности клиентов и возможности продукта и команды.
Благодаря этому команды разработчиков понимают, как они могут быстрее предоставлять ценность, а бизнес получает представление о зачастую огромном центре затрат, которым является инжиниринг.
Говорите с вашими пользователями
Распространенный антипаттерн в платформенном инжиниринге связан с тем, что инженеры платформ — тоже инженеры. Это означает, что они не имеют права думать, что знают все лучше всех, а мышление «платформа как продукт» предполагает общение с вашими внутренними пользователями. Действительно, отчет DORA за этот год показал, что команды, которые фокусируются на пользователях, получают 40%-ный рост производительности.
Если вы относитесь к своей платформе как к продукту, вы должны создавать ее постепенно, постоянно запрашивая обратную связь у своих внутренних разработчиков. По словам Грубер-Хазани, нужно спрашивать разработчиков, какие продукты, инструменты и языки им нравятся, а также какие они хотят использовать — что, в свою очередь, не только помогает в улучшении DevEx, но и способствует привлечению и удержанию кадров. Спросите своих разработчиков, хотят ли они перейти на контейнеры или какой вид мониторинга они хотели бы видеть на «золотом пути».
По словам Грубер-Хазани, этот «золотой путь» должен быть проложен в постоянном общении с вашими клиентами-разработчиками и должен включать в себя следующее:
- документация;
- поддержка;
- группы пользователей;
- отчеты об использовании;
- отчеты об ошибках;
- мониторинг;
- инжиниринг надежности объектов (SRE);
- новые возможности;
- отзывы.
Платформенный инжиниринг в крупных организациях
Но все это общие черты для большинства платформенных стратегий. Что же отличает крупные организации?
Чем сложнее ваша организация, тем сложнее структура ваших облачных расходов. Именно здесь FinOps становится обязательным элементом миграции в облако — чтобы иметь возможность отслеживать и оптимизировать, кто и сколько тратит в облаке. Эта сложность возрастает в крупных организациях, где наблюдаются интенсивные процессы закупок, включая закупки аппаратного обеспечения, серверов и лицензий. Масштабная FinOps требует бюджетирования и оповещения. Она также приводит к принятию различных решений. Грубер-Хазани привела пример того, как переход на виртуальную машину может стать способом снижения затрат по сравнению с облаком или как команды могут использовать локальные машины для работы без охранения состояния.
«Обычно крупные организации, которые пришли из эпохи дата-центров, все еще придерживаются прежних практик», — объяснила она и посоветовала начинать внедрять FinOps на ранних этапах, но искать финансы там, где они реально есть.
Еще один выявленный ею антипаттерн — начинать работу по «золотому пути» с самых сложных систем.
«Начиная с обновления более простых систем с меньшим количеством зависимостей, мы получим гораздо лучшие результаты, чем начиная с самой сложной системы с наибольшим количеством зависимостей», — сказала Грубер-Хазани. Это также позволяет добиться быстрых успехов, которые вдохновляют внутренних сторонников платформы.
Именно здесь на помощь приходит концепция минимально жизнеспособной платформы, когда вы создаете ее более мелкими шагами с жесткой обратной связью, чтобы убедиться, что создаваемое и поддерживаемое вами действительно нужно вашим пользователям. Не следует создавать слишком быстро что-то слишком сложное — это только увеличит технический долг.
Также важно делать маленькие шаги в создании «золотого пути», поскольку, по наблюдениям Грубер-Хазани, крупные организации часто внедряют дорогостоящие сервисы слишком рано, когда еще нет достаточной устойчивости и уверенности в платформе.
По ее словам, по мере роста зрелости платформы и перехода «ко второму дню» появляются новые требования:
- ротация SRE на вызовы и расследования;
- управление инцидентами;
- улучшенные конвейеры CI/CD;
- инфраструктура как код;
- DevSecOps;
- больше обучения для сопровождающих и пользователей платформы;
- межорганизационные архитектурные стандарты;
- бюджетная стратегия;
- FinOps-планирование и прогнозирование;
- безопасность во всем.
Наконец, Грубер-Хазани подчеркнула, что знание уменьшает страх, поэтому следует уделять больше времени воспитанию психологической безопасности, всегда давая пользователям представление о том, куда движется стратегия вашей платформы и как вы можете им помочь на этом пути.
«Речь не идет о замене людей», — сказала она, чтобы подчеркнуть, что автоматизация, особенно в крупных организациях, может вызывать страх потери работы. Этот новый «золотой путь» к облаку должен сопровождаться обучением новым необходимым навыкам.
И, независимо от размера вашей организации, необходимо постоянно собирать отзывы о том, что думают ваши внутренние клиенты.